How do you review an iPad Pro that’s visually identical to its predecessor and marginally improves upon its performance with a spec bump and some new wireless radios?
Let me try:
I’ve been testing the new M5 iPad Pro since last Thursday. If you’re a happy owner of an M4 iPad Pro that you purchased last year, stay like that; there is virtually no reason for you to sell your old model and get an M5-upgraded edition. That’s especially true if you purchased a high-end configuration of the M4 iPad Pro last year with 16 GB of RAM, since upgrading to another high-end M5 iPad Pro model will get you…16 GB of RAM again.
The story is slightly different for users coming from older iPad Pro models and those on lower-end configurations, but barely. Starting this year, the two base-storage models of the iPad Pro are jumping from 8 GB of RAM to 12 GB, which helps make iPadOS 26 multitasking smoother, but it’s not a dramatic improvement, either.
Apple pitches the M5 chip as a “leap” for local AI tasks and gaming, and to an extent, that is true. However, it is mostly true on the Mac, where – for a variety of reasons I’ll cover below – there are more ways to take advantage of what the M5 can offer.
In many ways, the M5 iPad Pro is reminiscent of the M2 iPad Pro, which I reviewed in October 2022: it’s a minor revision to an excellent iPad Pro redesign that launched the previous year, which set a new bar for what we should expect from a modern tablet and hybrid computer – the kind that only Apple makes these days.
For all these reasons, the M5 iPad Pro is not a very exciting iPad Pro to review, and I would only recommend this upgrade to heavy iPad Pro users who don’t already have the (still remarkable) M4 iPad Pro. But there are a couple of narratives worth exploring about the M5 chip on the iPad Pro, which is what I’m going to focus on for this review.
The M5 and Local AI Performance
As I mentioned above, the M4 and M5 iPad Pros are nearly identical, both externally and from a specs perspective. They look and weigh the same. The screen technology is the same (outstanding) Tandem OLED tech introduced last year. Battery life is the same. Cameras are unchanged.
The key difference is the M5 chip, which is based on a third-generation 3nm process, as opposed to the M4’s second-gen 3nm process. More specifically, there are new Neural Accelerators for AI built into each of the M5’s 10 GPU cores, which is where Apple’s claims of 3.5× faster AI performance compared to the M4 come from. The M5 also offers 12 GB of RAM rather than 8 GB on the base models, and 2× faster read/write speeds on the internal SSD made possible by the adoption of a PCIe 5 storage controller in place of the M4’s PCIe 4 controller. In addition to the M5, the new iPad Pro also comes with Apple’s new C1X cellular modem and N1 chip for wireless radios.
Apple’s bold claim with the M5 chip is that it was designed for intensive AI tasks, which should result in the aforementioned 3.5× performance improvement over the M4, or 5.6× compared to an M1 iPad Pro. The company also claims a big uplift in graphics workloads and rendering tasks thanks to the M5, such as 6.7× faster video rendering with ray-tracing than M1 (4.3× faster than M4) and 4.8× faster video transcoding than M4.
Because I’m not a video editor, I couldn’t put those video rendering stats to test. But I’ve been playing around with local LLMs for the past few months, so I was intrigued to corroborate Apple’s numbers and, importantly, understand if there are any practical benefits for power users on iPad.
Unfortunately, while Apple’s claims sound enticing, and the Neural Accelerators should improve AI tasks on a variety of fronts, such as token generation per second and prefill time (for time-to-first-token evaluations), these improvements have little to no practical use on an iPad Pro compared to a Mac right now. And it all comes down to the fact that, despite better multitasking and other features in iPadOS 26, there isn’t a strong app ecosystem to take advantage of local LLMs on iPad, beginning with Apple’s own models.
Before I share my results, let’s analyze Apple’s claims so we can understand where they’re coming from.
Apple conducted AI tests on an iPad Pro with 16 GB of RAM and measured time to first token with “a 16K-token prompt using an 8-billion parameter model with 4-bit weights and FP16 activations and prerelease MLX framework”. You’ll notice a couple of things here. For starters, Apple doesn’t say which app they used to test an MLX-optimized LLM on iPad (I assume it was an internal testing app), and notably, they’re not saying which model they actually used. But when I read that line, it rang a bell.
When Apple introduced their Foundation models last year, they mentioned in a footnote that they compared their model against a variety of other LLMs, including (among others) Llama-3-8B-Instruct. Llama 3 was released in April 2024, and at first, I assumed that Apple repeated their tests with the same model for the M5 iPad Pro. However, Llama 3 only offered an 8K context window, and Apple is saying that they tested a 16K context window for the M5. Therefore, my assumption is that Apple benchmarked either Meta-Llama-3.1-8B-Instruct-4bit or Qwen3-8B-MLX-4bit, both of which happen to be available on the MLX Community page on Hugging Face.
Naturally, I wanted to test these models myself and see if I would have any practical use cases for them with my iPad Pro workflow. But I immediately ran into a series of problems, for which only Apple is to blame:
- There is no official, Apple-made Terminal app for iPad that lets you install open source projects like MLX or other local LLM utilities.
- Apple’s MLX framework is incredible on macOS; however, the company hasn’t released an official MLX client that AI developers and enthusiasts can use on an iPad to test it.
- I wasn’t able to find an MLX-compatible third-party app that also showed me key metrics such as tokens per second (tps), time to first token (TTFT), or milliseconds per token (ms/t). All of these tools exist on macOS because you can easily install software from the web; none of them can be installed on the iPad, and due to the economics of the platform, third-party developers aren’t making them, either.
- Does anyone know if Apple’s Foundation model has been optimized for MLX? Does anyone know the actual size of their latest local model? Is it different from 2024? Why isn’t Apple sharing a bigger, 8B model for devices that can run it, like the M5 iPad Pro? I continue to have so many questions about Apple’s Foundation models, and the company isn’t sharing any new details. As I keep saying on AppStories, if Apple wants to be taken seriously in AI, they need to be more transparent about their work. The fact that I had to do a lot of digging to guess which models Apple used for benchmarks of the M5 says a lot. In any case, the offline Foundation model can’t be used for benchmarks, so there’s that.
This is the paradox of the M5. Theoretically speaking, the new Neural Accelerator architecture should lead to notable gains in token generation and prefill time that may be appreciated on macOS by developers and AI enthusiasts thanks to MLX (more on this below). However, all these improvements amount to very little on iPadOS today because there is no serious app ecosystem for local AI development and tinkering on iPad. That ecosystem absolutely exists on the Mac. On the iPad, we’re left with a handful of non-MLX apps from the App Store, no Terminal, and the untapped potential of the M5.
In case it’s not clear, I’m coming at this from a perspective of disappointment, not anger. I strongly believe that Apple is making the best computers for AI right now – but those computers run macOS. And I’m sad that, all things being equal, an iPad Pro with the M5 doesn’t have access to the breadth of open-source tools and LLM apps that are available on macOS.
Nevertheless, you know me: I wasn’t going to let it go.
Testing Local Models with llama.cpp
Although Apple reported their benchmarks with an MLX model, I figured I’d be able to see some improvements in inference time and TTFT with models written in the GGUF format, too. After even more research in a very fragmented App Store ecosystem, I decided to test PocketPal AI, an open-source LLM app that can run GGUF models thanks to llama.cpp. It’s not MLX, but I thought, ”Why not?”
For starters, model size: I was not able to load models larger than 8B ones quantized in 4-bit. For example, I really wanted to try the “small” Qwen3-Coder-30B on the M5 iPad Pro, but that wouldn’t load. Oddly enough, Qwen3-8B-gemini-2.5-pro-distill did not load on the M5, either.
So for my PocketPal tests, I ended up using Qwen2.5-3B-Instruct and Llama-3.1-8B-Instruct-Q4. PocketPal has a “memory lock” feature that forces the system to keep the model in RAM rather than using compression or swapping; I enabled it since I figured it’d also be a good test for the increased 153GB/s memory bandwidth of the M5, a nearly 30% improvement over the M4. Additionally, PocketPal has a “Metal-accelerated API” that can be enabled in Settings, which I tested with Qwen2.5-3B-Instruct first at 50 GPU layers, then at 100. Also, for Qwen2.5-3B-Instruct, I first used a 1,100-token prompt, then a 5,400-token one.
For my Llama-3.1-8B-Instruct-Q4 tests, having seen the results from Qwen, I decided to only try a long prompt (where I figured I’d see more gains in prefill time) with PocketPal’s GPU layers set to 100.
Here are the results:
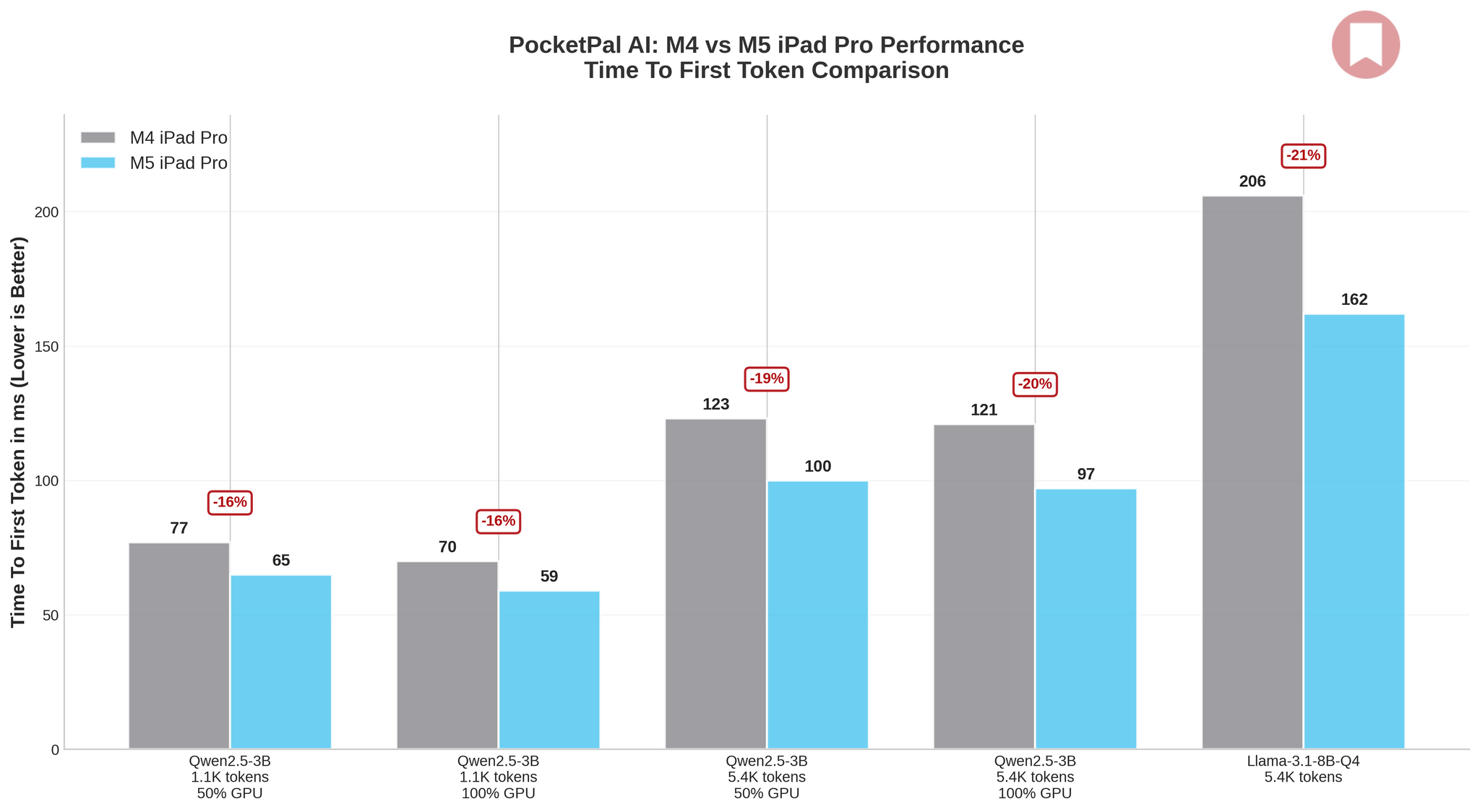
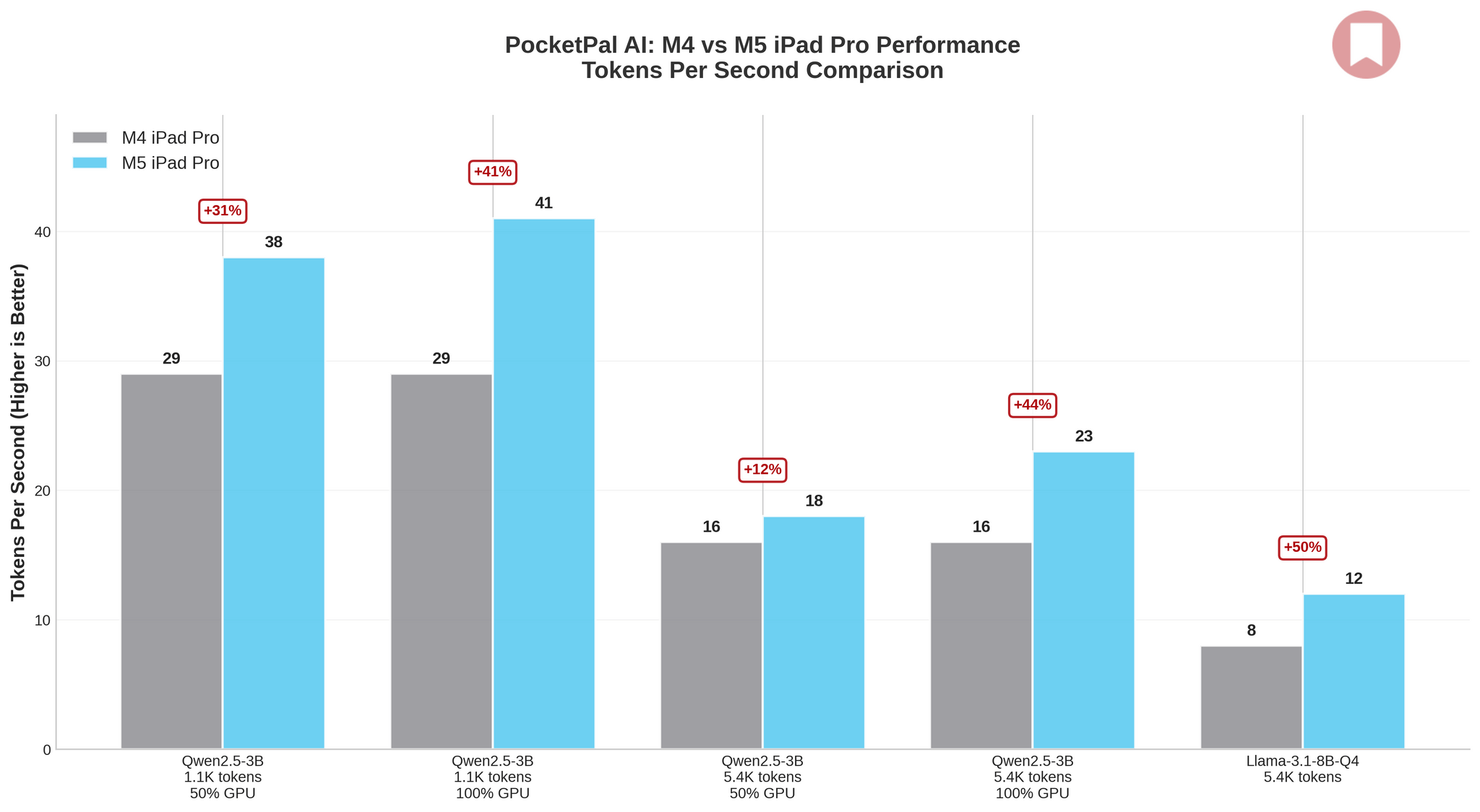
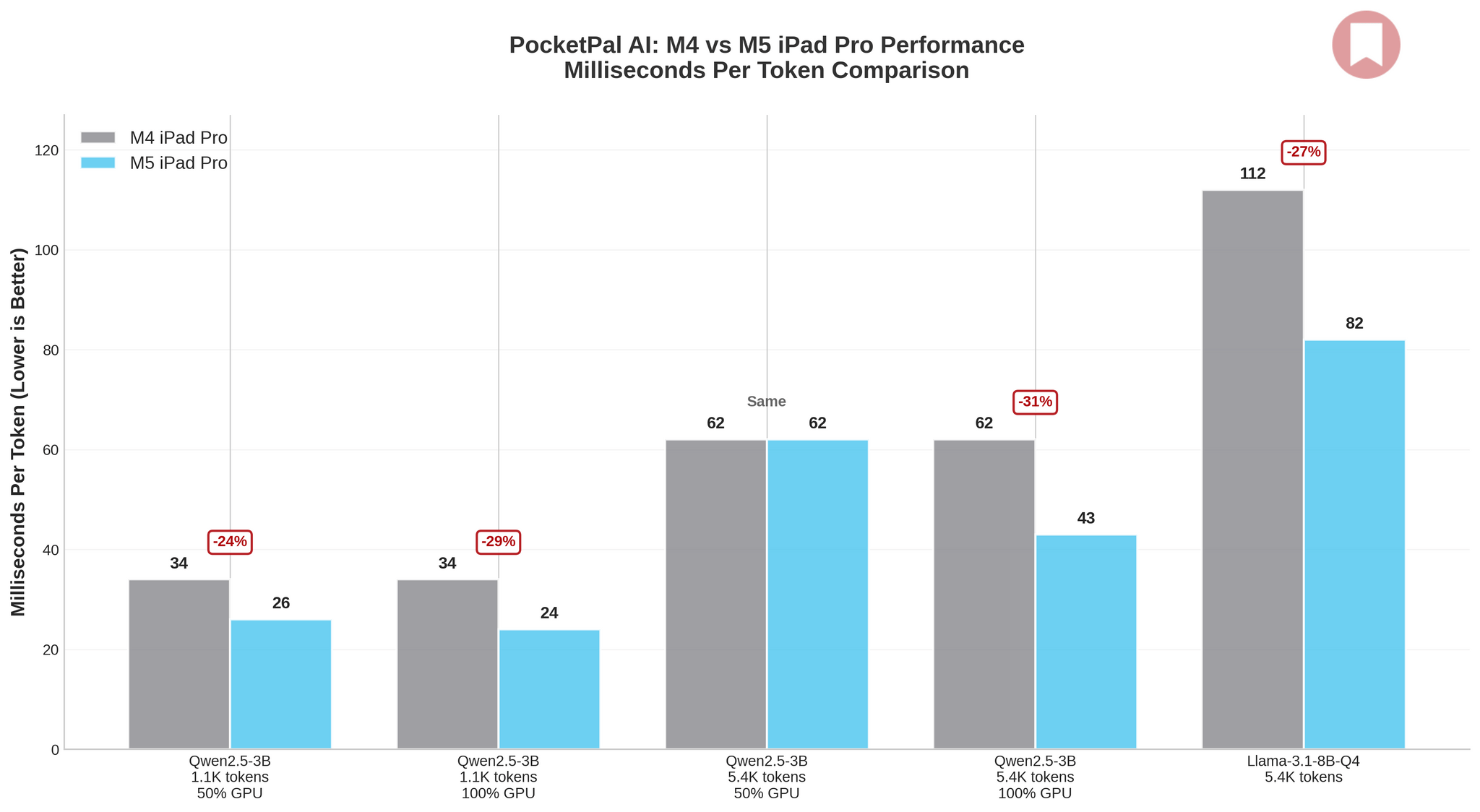
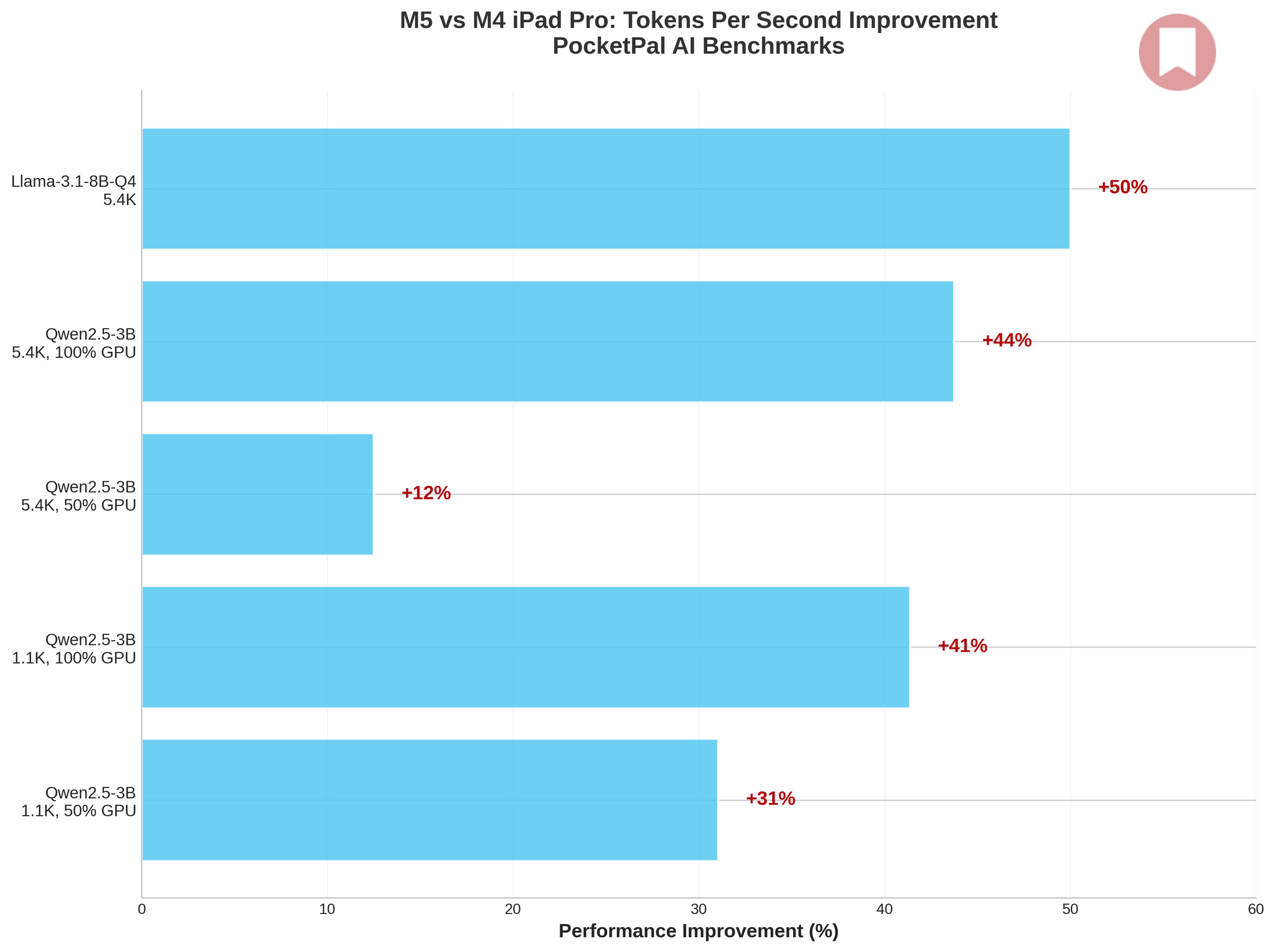
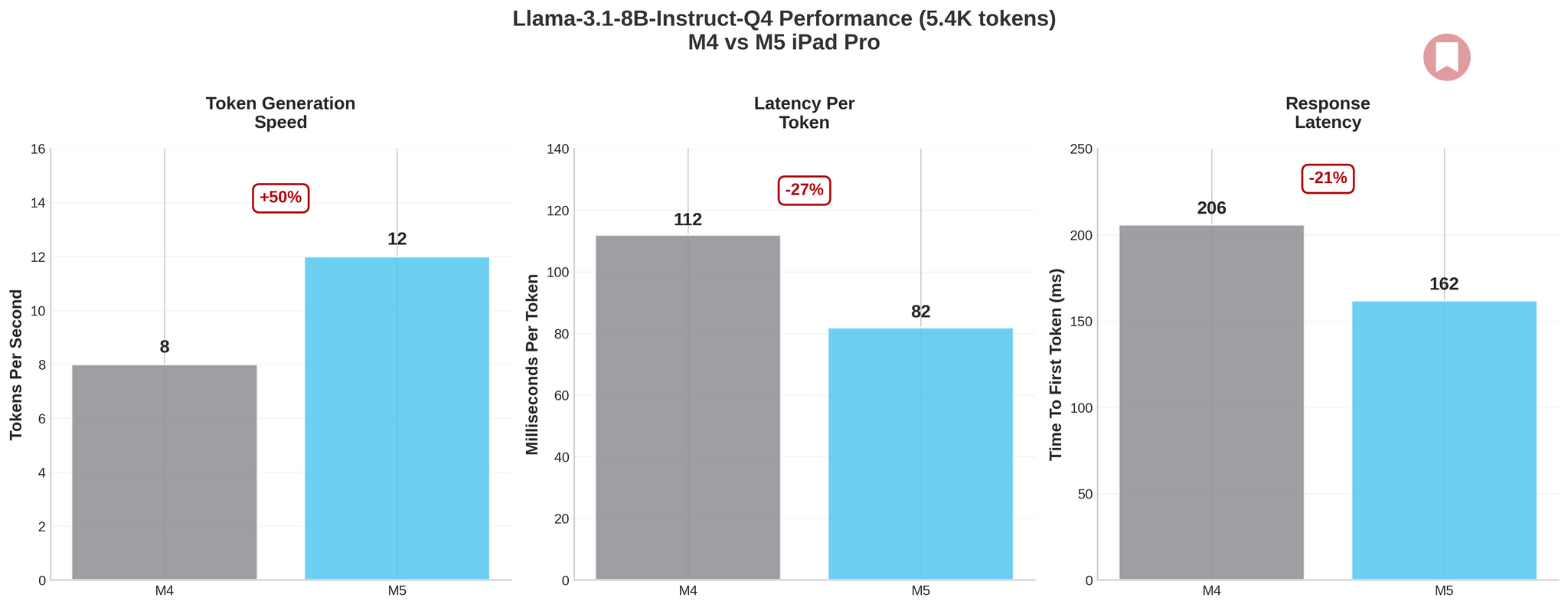
The results are clear, if modest: across my tests, the M5 delivered 1.1× to 1.5× improvements over the M4 – a far cry from Apple’s “3.5x faster AI” marketing claim. Initially, I assumed that was because I couldn’t find a third-party iPad app that supported MLX models and showing statistics when running them.
The biggest win was with Llama-3.1-8B-Instruct-Q4, where I saw a 50% jump in tokens per second (from 8 to 12 tps) and a 27% reduction in per-token latency. Qwen2.5-3B-Instruct showed similar gains, particularly with 100% GPU layers enabled, where I measured 31–44% improvements depending on prompt size. Longer prompts and full GPU acceleration consistently confirmed the M5’s overall baseline gains.
Here’s the thing, though: 12 tokens per second is more responsive than 8, but it’s not a transformative leap – and it pales in comparison to what can be achieved with MLX tools on macOS. Apple’s 3.5× claim seems to apply to very specific workloads, especially the ones that have been fine-tuned for MLX. But for practical LLM inference with llama.cpp – the one that you can easily find on the iPad App Store these days – you should expect incremental improvements, not a revolution, with the M5.
Still, I wasn’t ready to give up.
Making a Custom MLX App for iPad
Since I couldn’t verify Apple’s claims of 3.5× faster LLM inference on the M5 with public apps from the App Store, I commissioned a custom app for this review. I teamed up with Finn Voorhees, who built MLXBenchmark, a simple utility that can install the latest MLX models from MLX Community on Hugging Face, allowing you to chat with LLMs and capture real-time stats for each conversation.
I’m going to share my findings below, but it was immediately clear to me when I started comparing the performance of MLX across the M4 and M5 that something wasn’t adding up: I kept getting largely the same numbers between the old and new iPad Pro, with marginal gains on the M5 that were far below Apple’s claims.
So I did more digging, and I realized something I’d originally ignored: Apple benchmarked models running on the M4 and M5 iPad Pros with a pre-release version of MLX that is not available to the public yet. This key detail was also confirmed by one of the co-creators of MLX, who said that “much faster prefill” (i.e., how time to first token typically goes down) will be made possible by “a future release” of MLX.
Where is this “future release”, you may ask? This is where the story gets interesting.
My understanding is that full MLX support for Neural Accelerators in the M5 will be rolled out later this year. A new branch of the MLX open source repository has just added initial support for Neural Accelerators in the M5, and it can be tested on the M5 MacBook Pro since it has a Terminal, can install the latest code from the GitHub repository, and can run mlx-lm.
On iPad, it’s a little less clear. In theory, if developers want to use the new Neural Accelerators for low-level calculations, they can already use existing APIs (CoreML, TensorOps, Metal Performance Shaders) to do so. In practice, if they want to build an LLM app that does that with MLX, they have to go through multiple levels of dependencies and commits for the MLX branch that was released last night. I know, because we did with MLXBenchmark. And even then, the results that I got when testing different models were inconclusive and far below a 3.5× improvement, which makes me wonder whether neural-accelerated MLX inference can work at all on an iPad Pro right now with this early branch.
As things stand now, I witnessed the same ~1.2× marginal improvements with MLX on the M5 iPad Pro that I saw with a llama.cpp backend. Here are the numbers I benchmarked with our own MLXBenchmark app running Qwen3-8B-4bit on the M4 and M5 iPad Pros with the experimental, Metal-accelerated MLX branch:
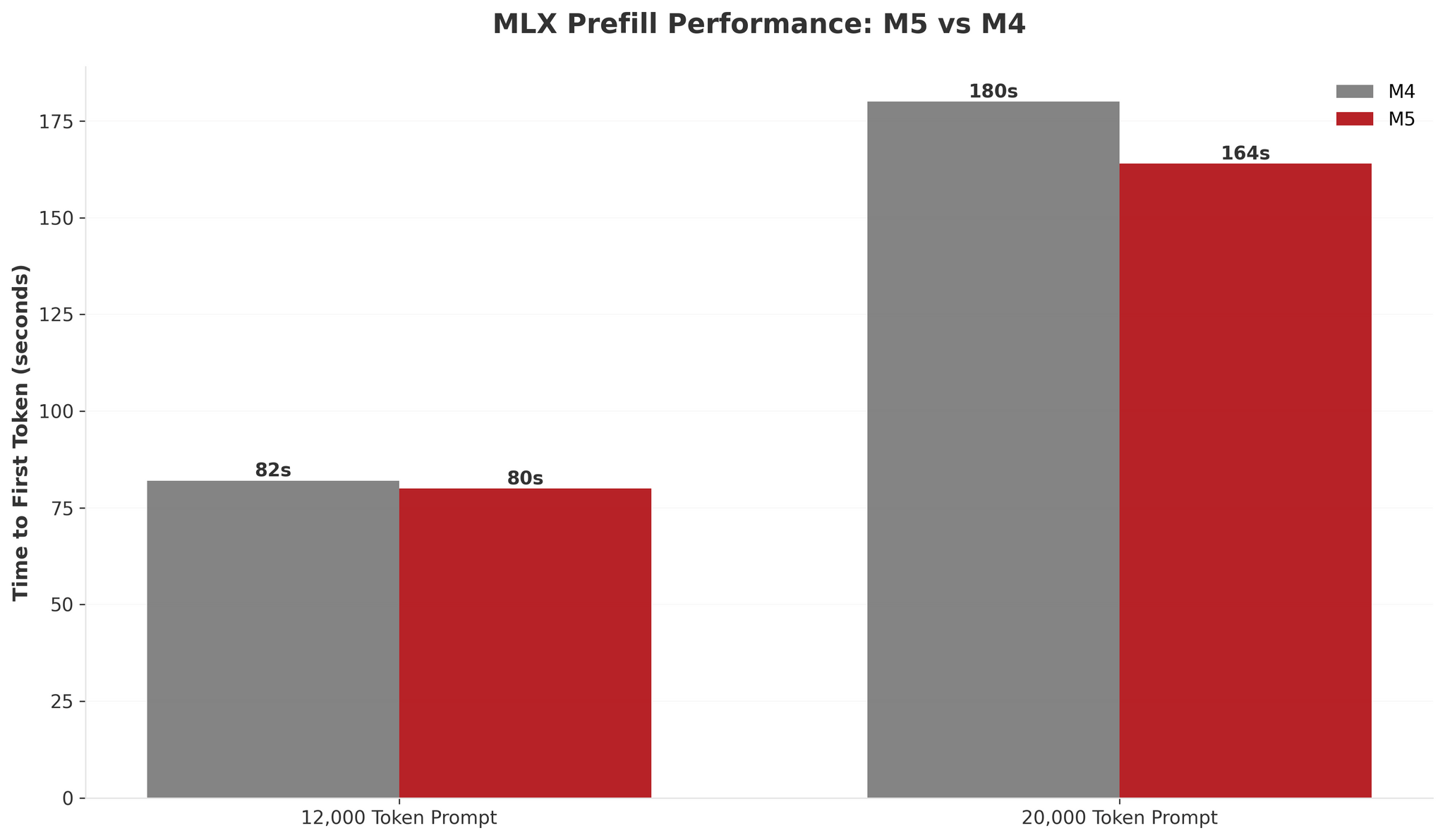
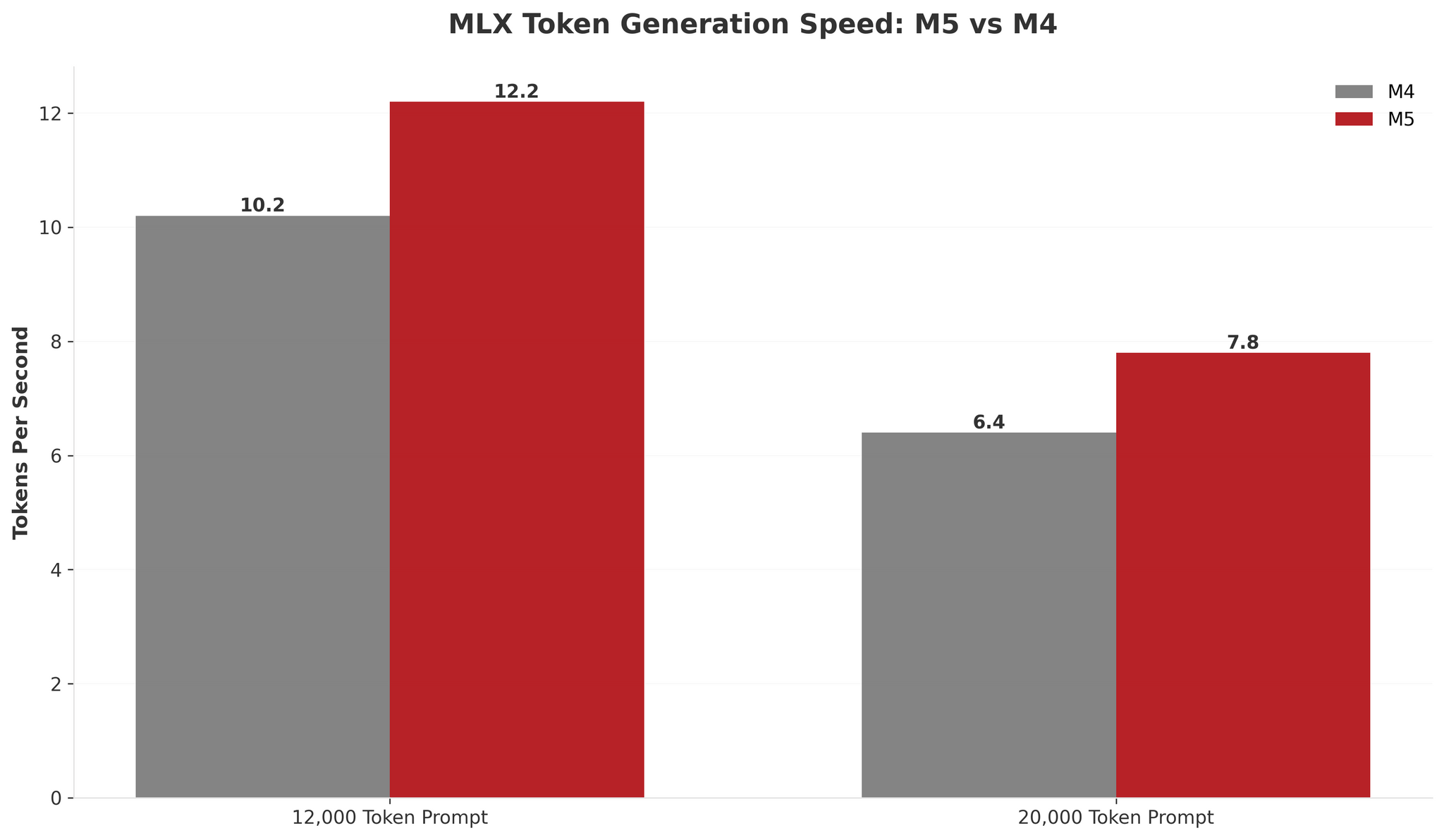
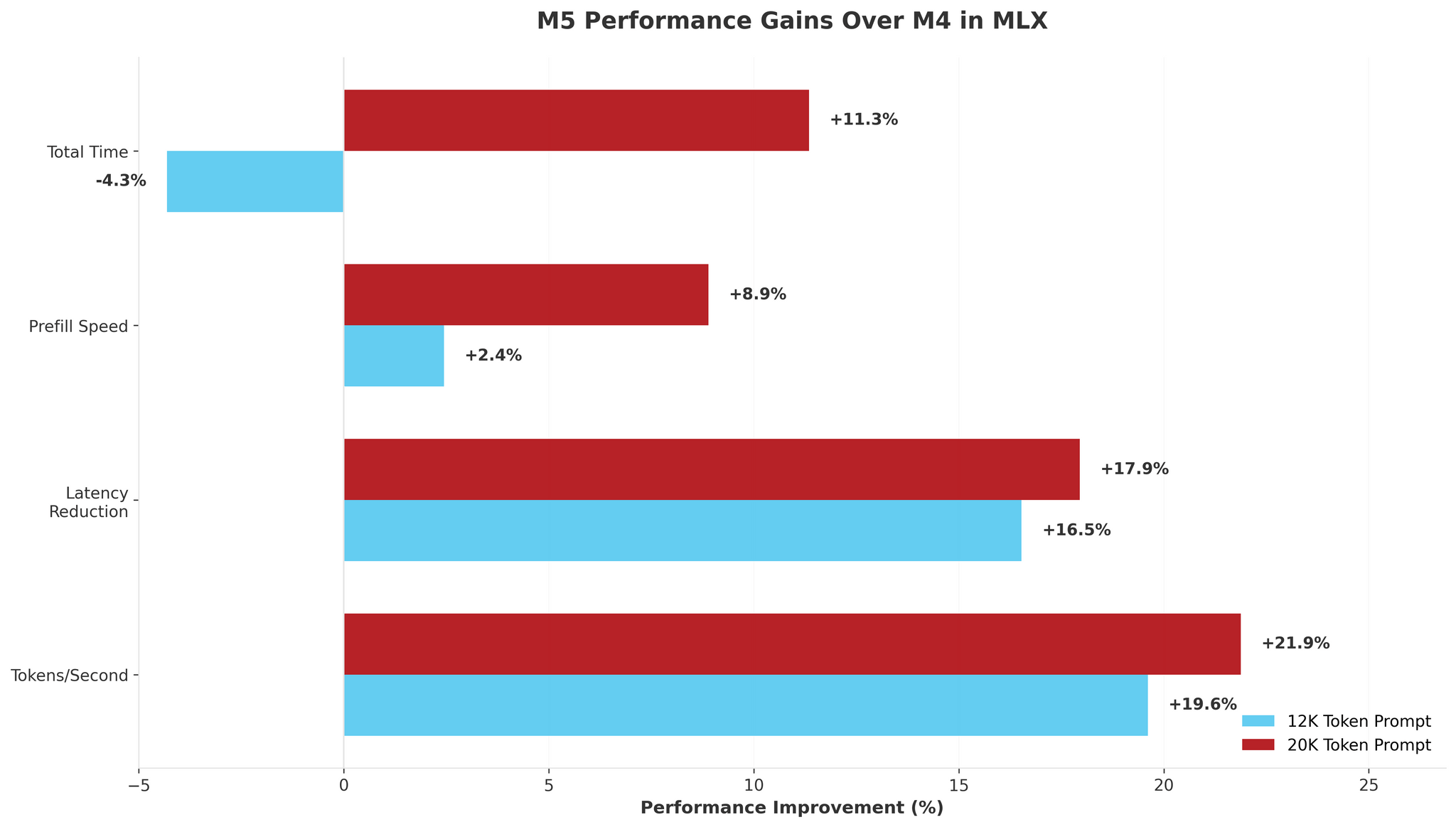
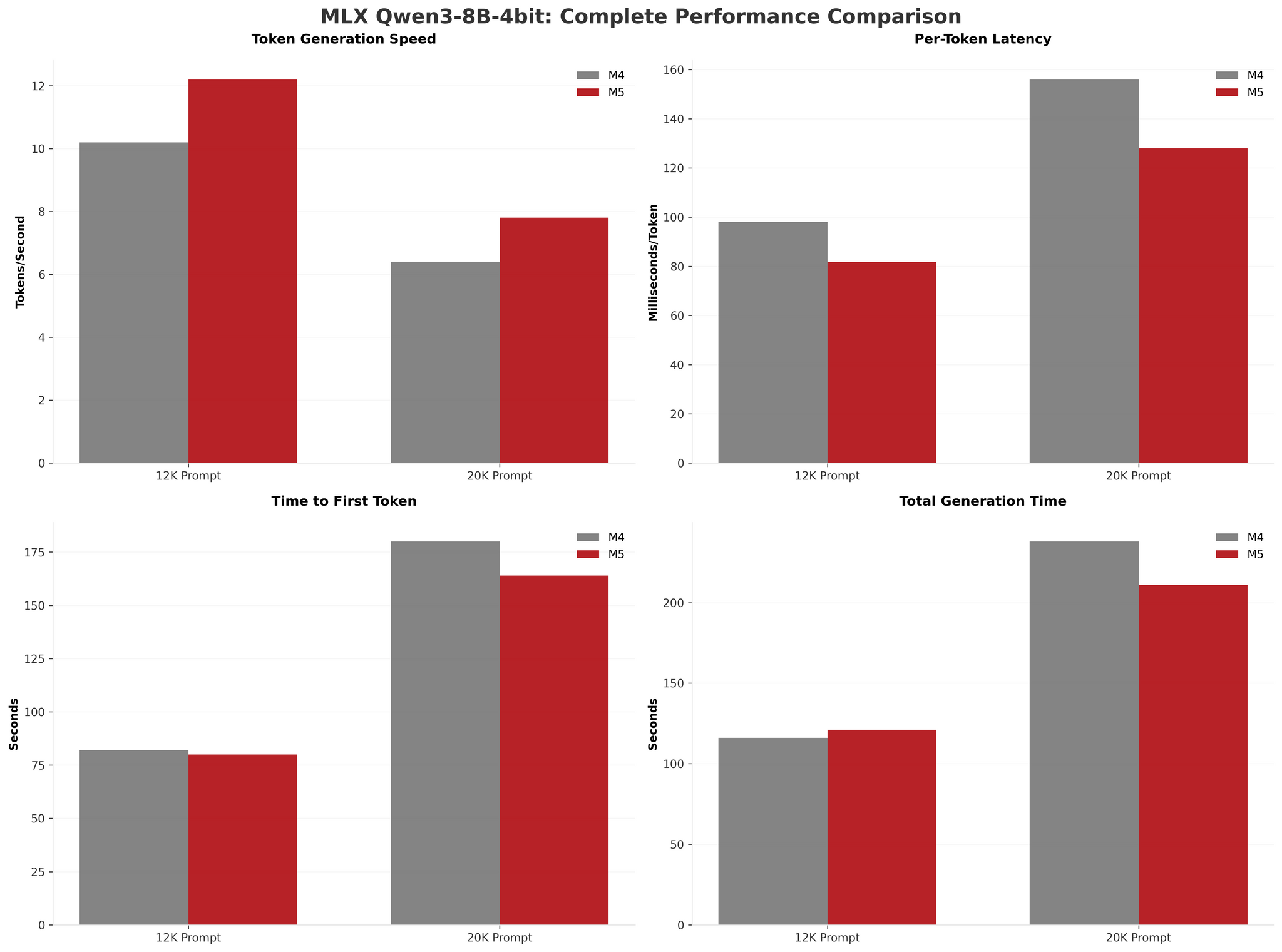
As you can see, the M5 delivered 1.2× improvements in token generation (12.2 tokens/s vs 10.2 tokens/s) and barely any improvement in time to first token with shorter prompts. This 20% gain is nearly identical to my llama.cpp results, suggesting both frameworks are benefiting from the M5’s faster memory bandwidth and GPU cores.
The story is slightly different with longer context windows: longer prompts seem to hint at the M5’s memory bandwidth advantage more clearly. With a 20,000-token prompt, the M5 reduced prefill time by 16 seconds (9.8% faster) compared to just 2 seconds with a 12K prompt, which to me suggests the M5’s ~30% bandwidth increase becomes meaningful at scale. But even at 20K tokens, the 1.22× generation speed was nowhere near Apple’s 3.5× claim.
Despite us using the latest MLX branch with MLXBenchmark for iPad, I did not experience a 3.5x speedup in local inference. I’d love to know if any other iPad app developer can figure this out.
I look forward to testing Apple’s upcoming version of MLX fully optimized for the M5 iPad Pro, and I’m particularly keen to see how its new architecture can improve the prefill stage and time to first token.
I know for a fact that the Neural Accelerator-based performance gains are real: image generation tasks in DrawThings (which worked closely with Apple to offer M5 support at launch) were 50% faster on the new iPad Pro thanks to the M5. My only issue is that I find image generation and so-called “AI art” fundamentally disgusting, and I’m more keen to play around with text-based LLMs that I can use for productivity purposes. You won’t see me cover AI image generation here on MacStories.
Today, with the LLM apps from App Store I could find, and the custom one we built for the current version of MLX, I could only get a 1.2× improvement over the M4 in real-world LLM inference tasks.
Unfortunately, even once Apple launches the new version of MLX, I’m worried that it still won’t change the fact that there isn’t a strong ecosystem of apps on iPad that will take advantage of the M5 for AI tasks. Until Apple builds a Terminal app for iPad, allows for side-loading of software from the web, or fosters a vibrant ecosystem of new native iPad apps (or all of the above), the M5’s AI gains on iPad will remain largely theoretical and not practical.
Enough About AI, What About Multitasking?
Right. I was hoping to see some interesting gains enabled by the M5 for windowing and multitasking, but that wasn’t the case.
On the M5 iPad Pro, I could still only open 12 windows at once in the workspace before one of them would be jettisoned back to the app switcher. Even then, just like on the M4 before, I could see some definite performance degradation when all 12 windows were open at once: things would get choppy on-screen, frame rate started lagging in certain Liquid Glass animations – you know, the usual.
The multitasking and windowing experience of the M5 iPad Pro is essentially the same as the M4, despite the improvements to the new chip and faster memory. I’m not ready to say that Apple has hit a performance wall with their new iPadOS windowing engine already, but at the same time, I’m not sure why Macs with 16 GB of RAM and much older chipsets could keep a lot more windows open at once back in the day.
The M5 and Gaming
I also wanted to test the M5’s improvements for high-end gaming on the iPad Pro. However, similarly to the AI story, I ran into limitations caused by the absence of games on the iPad App Store compared to Steam for Mac as well as a lack of games that had been updated to take advantage of the M5’s architecture.
Theoretically, the M5 supports third-generation ray tracing with 1.5× faster rendering than the M4 and 6.7× faster ray-traced rendering than the M1. In practice, I could not find a single iPad game that featured both MetalFX upscaling and ray tracing. There are AAA games that have been updated for Apple silicon and which support ray tracing, such as Cyberpunk 2077 and Control; however, those games are Mac-only and cannot be installed on iPad. It’s quite telling, I suppose, that the only demo I saw for a game that supported 120 fps and ray tracing on the M5 iPad Pro was Arknights: Endfield, which is launching in 2026.
As a result, I was left testing the few AAA games for iPad that do support Metal-based upscaling, but which don’t offer Metal-based frame interpolation or ray-traced rendering. In my tests, performed with the iPad Pro connected to my Mac Studio and running the MetalHUD overlay to monitor stats, I observed the same performance from the M4 and M5, with nearly identical numbers between the two. I played both Resident Evil 4 and Assassin’s Creed: Mirage, with the latter set to ‘High’ graphical settings and 100% rendering resolution with the MetalHUD overlay. Both games were running at 30 fps – a hard cap imposed by the games’ developers that didn’t allow me to bump the frame rate higher even if I wanted to.
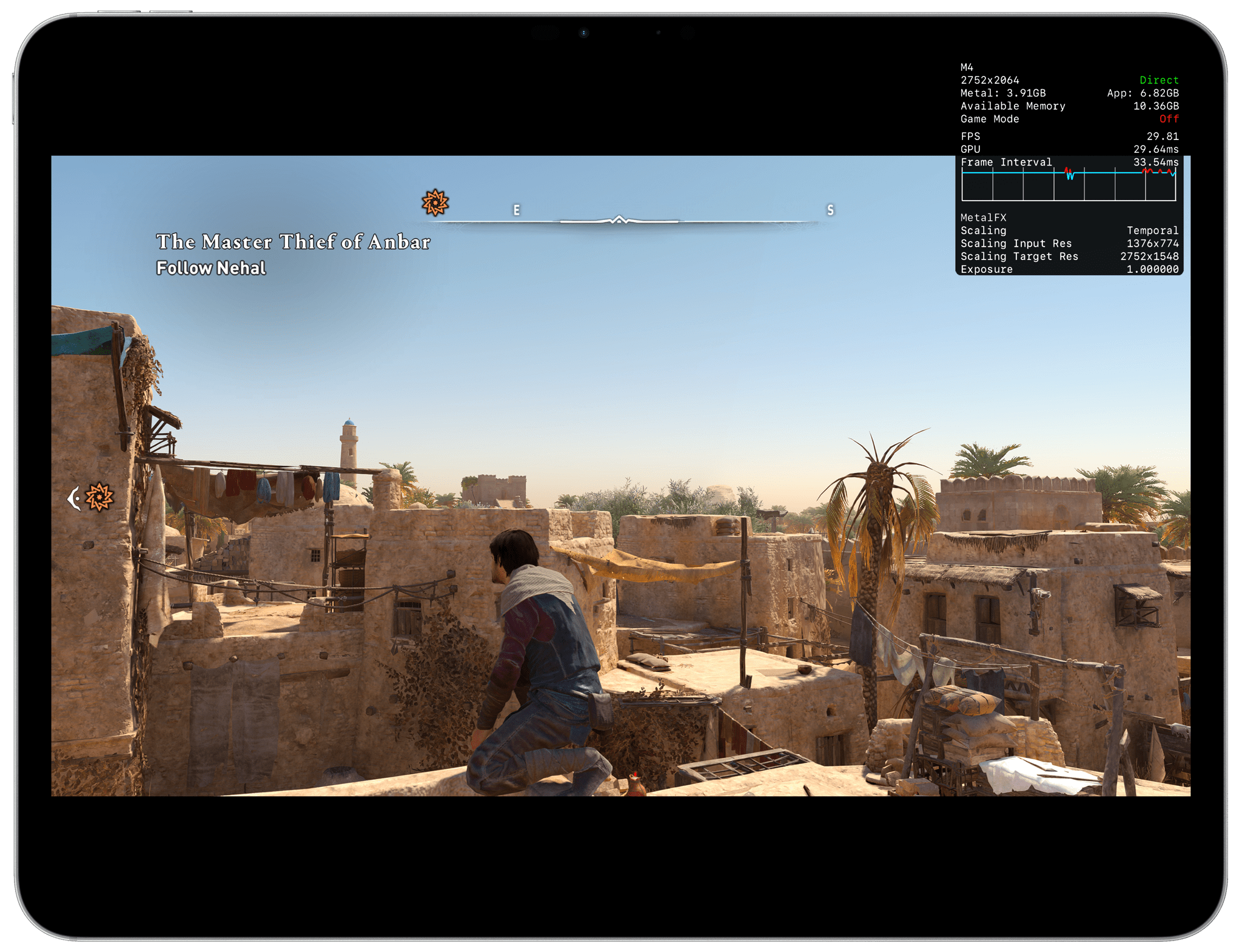
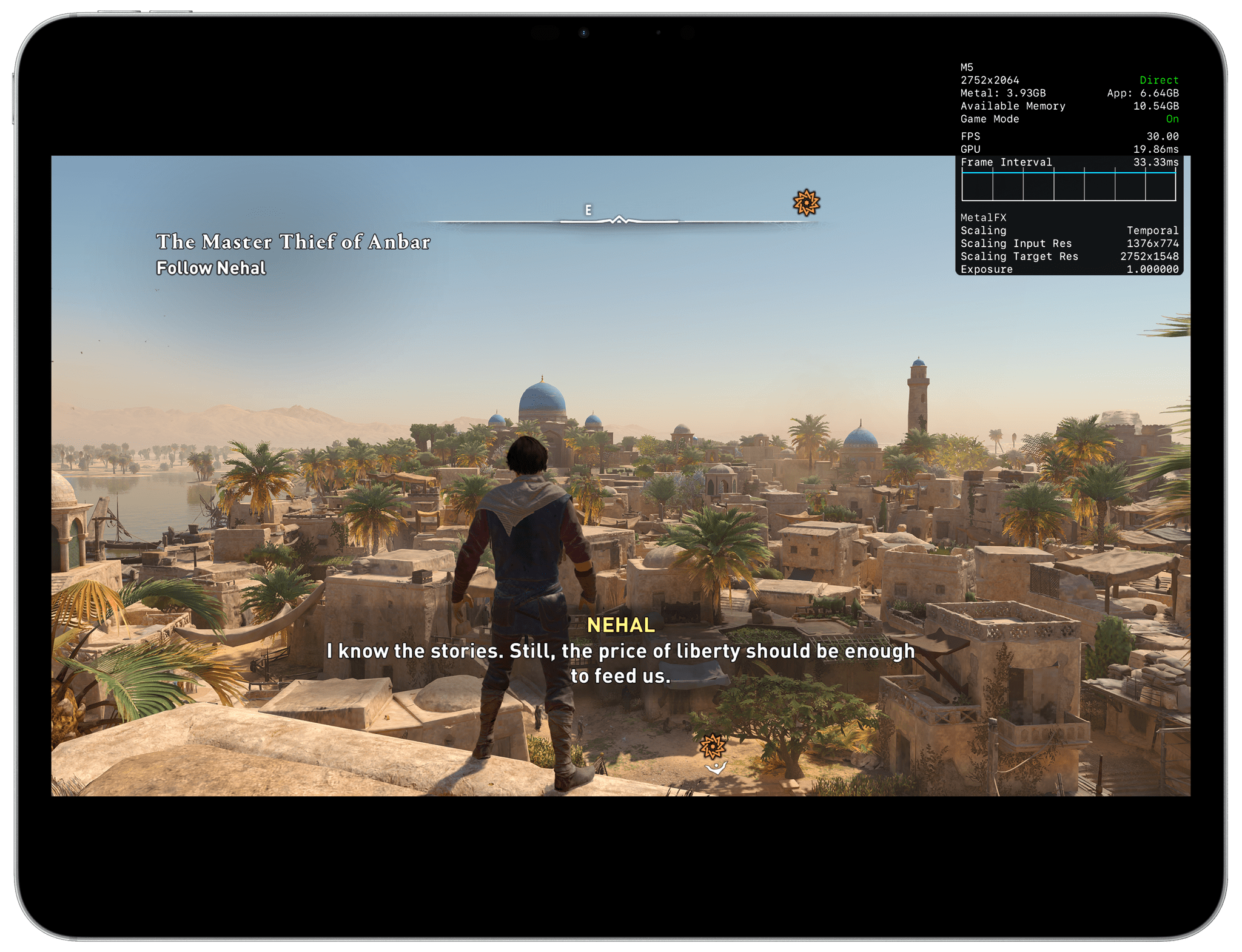
On the M5, GPU rendering times were slightly lower, but overall performance was comparable to the M4.
Interestingly, Resident Evil 4 showed that the GPU inside the M5 was more powerful than the M4’s with a rendering time of 8 ms for each frame compared to the M4’s 28–30 ms rendering time. Essentially, that meant that the M4’s GPU took 3.5× more time to render each frame than the M5. However, this performance gap between M4 and M5, while impressive, is meaningless: again, due to how the game was developed for iPadOS, both iPads delivered identical frame rates. The M5’s GPU was simply sitting idle most of the time, and although it was rendering each frame more quickly than the M4, the game’s engine didn’t allow me to choose a higher frame rate. Assassin’s Creed ran the same across the M4 and M5, and neither game supported Metal frame interpolation or ray tracing.
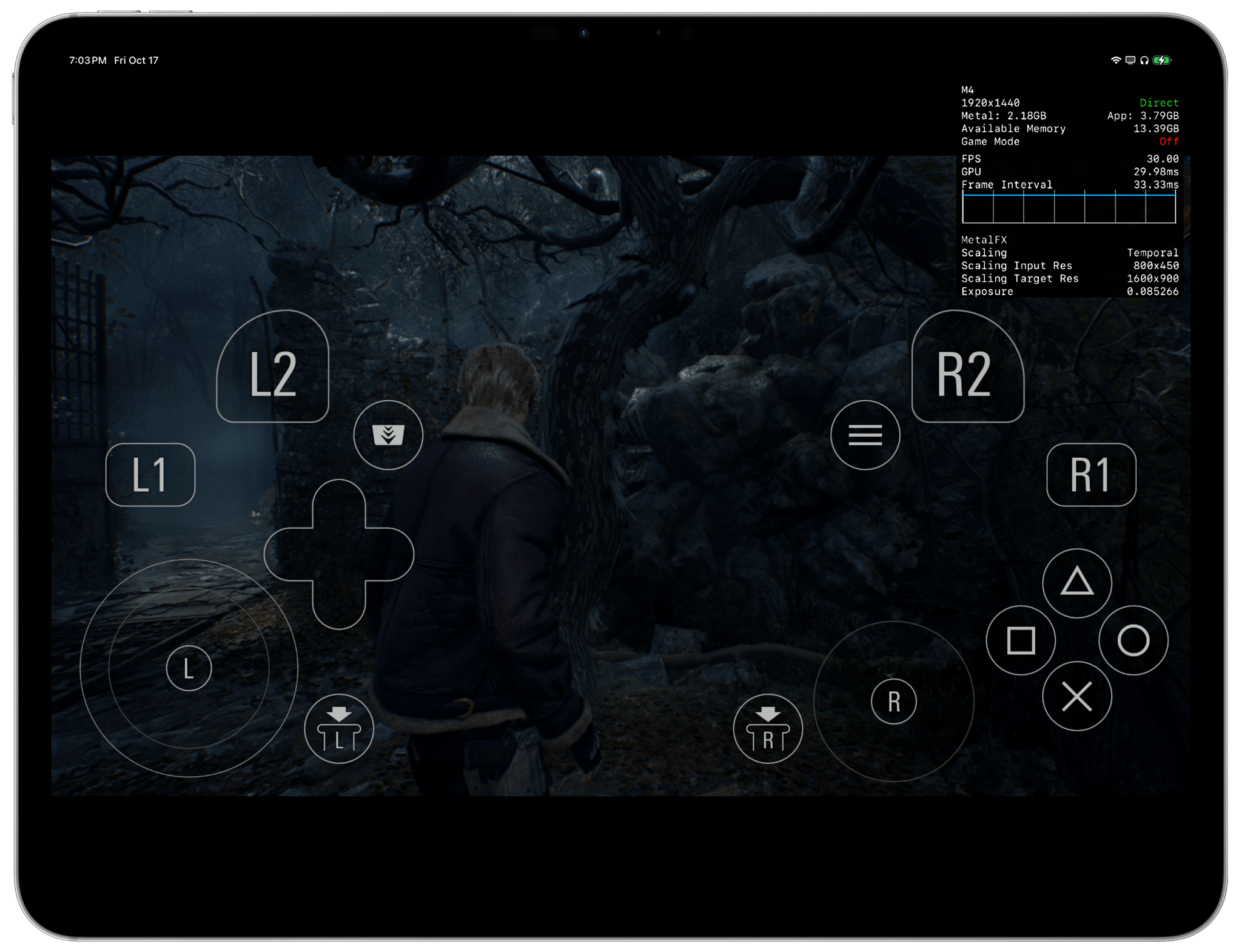
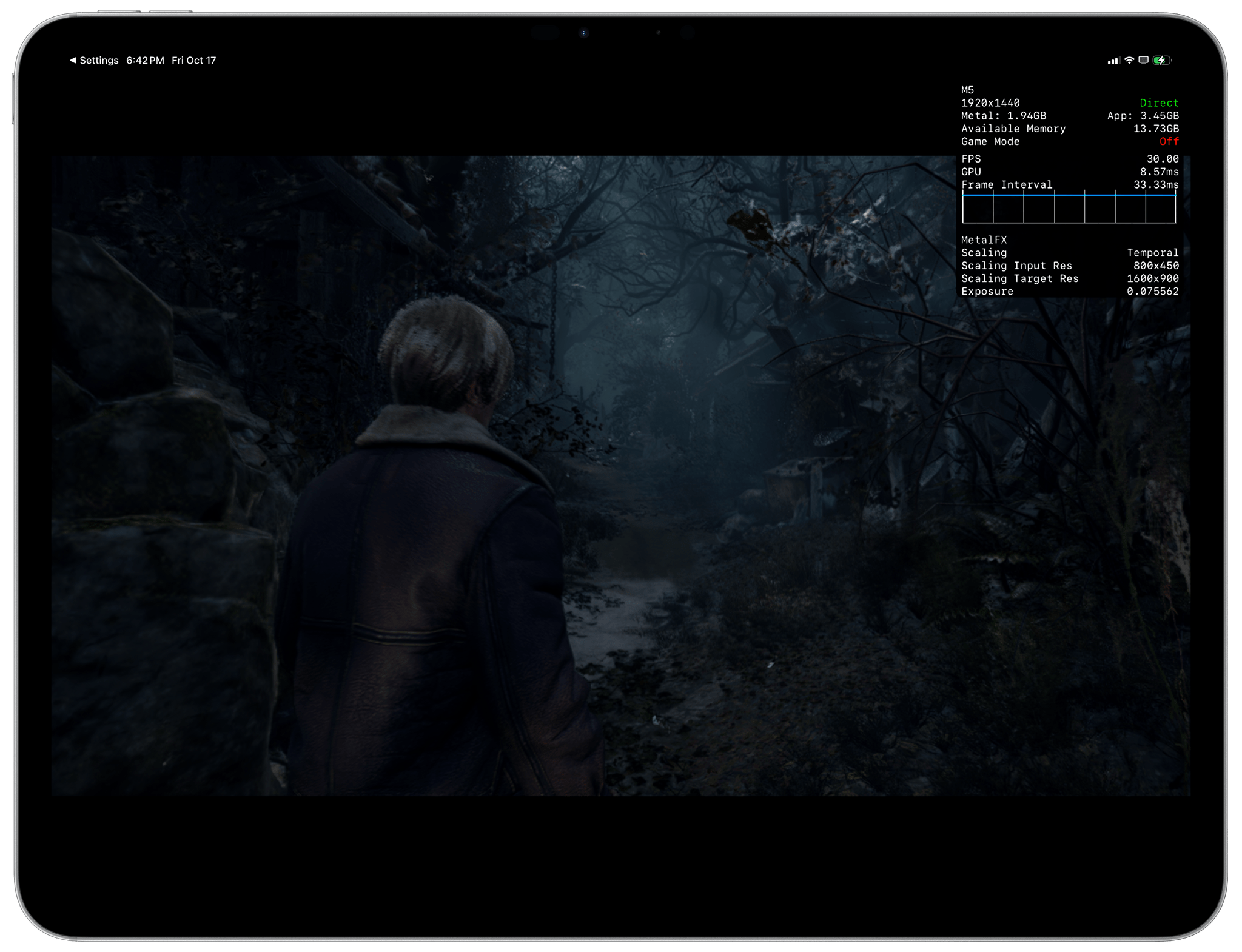
Resident Evil 4 looked terrible on both the M4 and M5, but at least the M5’s GPU showed faster rendering times.
So once again, we go back to the same idea: until developers rebuild their iPad games to tap into the M5’s capabilities, or until Apple fosters a richer ecosystem of console-quality games on iPad, Apple silicon’s improvements for game rendering will remain objectively real, but also theoretical since nobody is taking advantage of M-series chips for gaming to their full extent.
This is a larger story that goes beyond the scope of this review when it comes to Apple and gaming. The company has created a remarkable piece of silicon that could allow for console-quality gaming with modern features like ray tracing and frame generation on a fanless computer that has an OLED display with a 120Hz refresh rate and is 5mm thin. But since there are no games that unlock the true power of Apple silicon yet, Apple has very little to show for it on iPadOS.
Fast Charging, External Displays, and More
Some of my favorite moments when testing the M5 iPad Pro came from smaller quality-of-life improvements that had a real, measurable impact on my daily workflow.
First up, fast charging. New in the iPad Pro this year, Apple says that the M5 now supports fast charging up to 50% in 30 minutes when using a 60W power adapter or higher. I can confirm that this is accurate and a fantastic change when you’re working on the iPad Pro all day. I tested fast charging with this 160W UGreen power adapter and a 100W-certified USB4 cable, and I could indeed charge up to 50% in 30 minutes with the iPad’s display turned off on the Lock Screen. Although it would have been nice to see fast charging up to 100W like on other modern laptops and phones, I’ll happily take a 50% charge in 30 minutes. It’s more than enough to get me through several hours of work, and I’m glad to see that the feature is not exclusive to Apple’s new dynamic charger.
Second, the M5 iPad Pro can now drive external displays at 4K resolution and a 120Hz refresh rate with Adaptive Sync. While Apple itself doesn’t make a 4K@120Hz display (yet?), I own a 27” 4K OLED monitor that refreshes at 240Hz and is G-Sync compatible, so I was keen to see if this change would be supported (a) on non-Apple displays and (b) with USB-C cables instead of Thunderbolt ones.
I’m happy to report that it worked perfectly in my tests and I didn’t have to change anything in my setup to take advantage of faster refresh rates. As soon as I connected the iPad Pro to my ASUS monitor, the resolution stayed at 4K, and the refresh rate was immediately bumped to 120Hz, resulting in faster and smoother animations out of the box with my existing USB4-certified cable. This is an excellent change; when I connect the M5 iPad Pro to my desk setup, I no longer have to sacrifice the quality of the iPad’s internal ProMotion display, and I can enjoy the same, smooth iPadOS animations on the ASUS monitor as well. It feels, effectively, like using a ProMotion display not made by Apple.
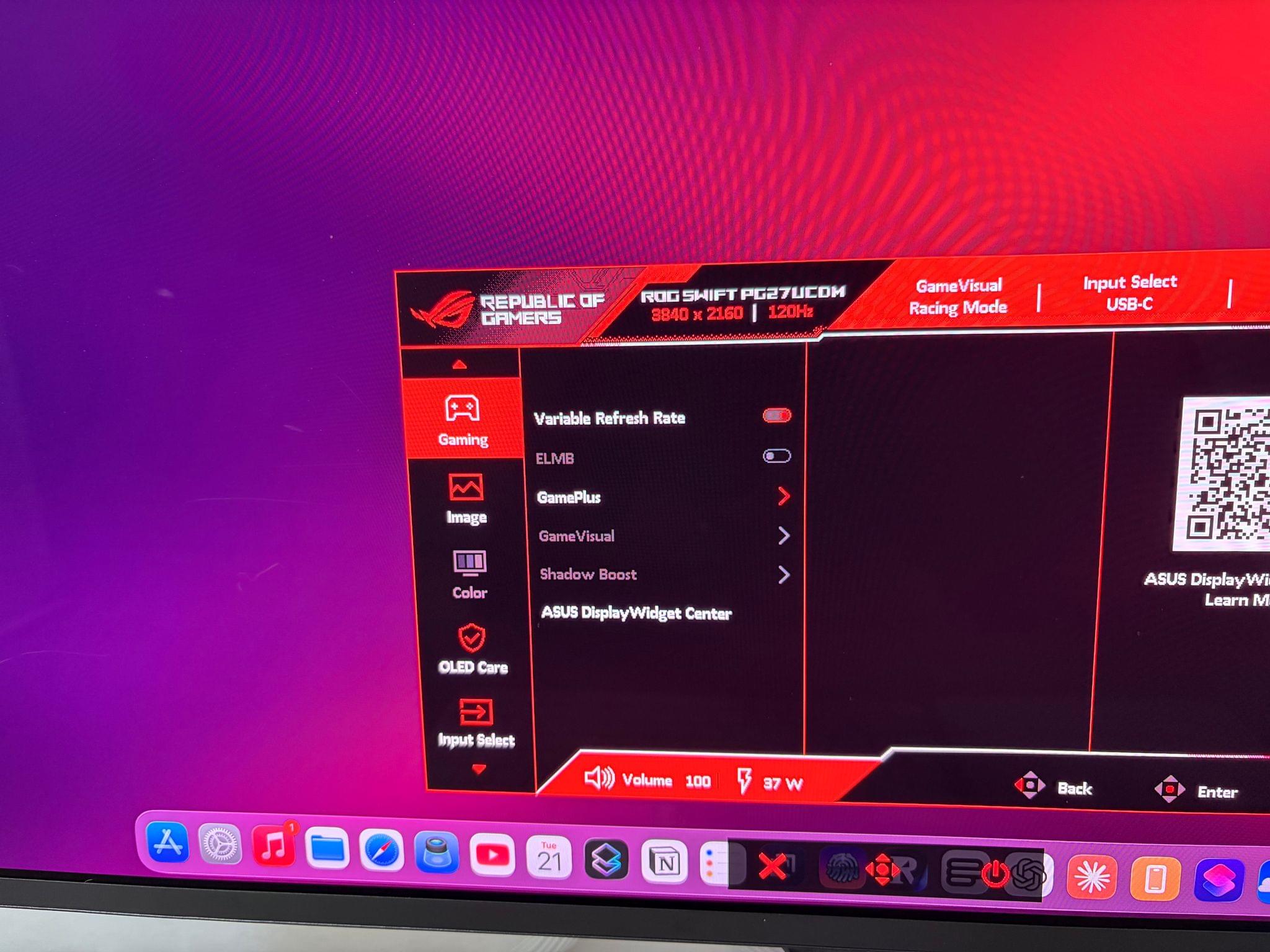
For compatible displays, Apple is also introducing a new option called ‘Adaptive Sync’ that is their own take on variable refresh rate. In case you’re not familiar with this feature from the PC gaming world, it is designed to reduce latency; it removes hard refresh rate limits and instead makes a connected display refresh at a variable refresh rate that changes in real time based on what you’re doing. In my case, I observed that with Adaptive Sync enabled, the monitor’s refresh rate would stay idle at 81Hz. As soon as I moved the iPadOS pointer or any window on-screen, the refresh rate would instantly shoot back up to 120Hz.
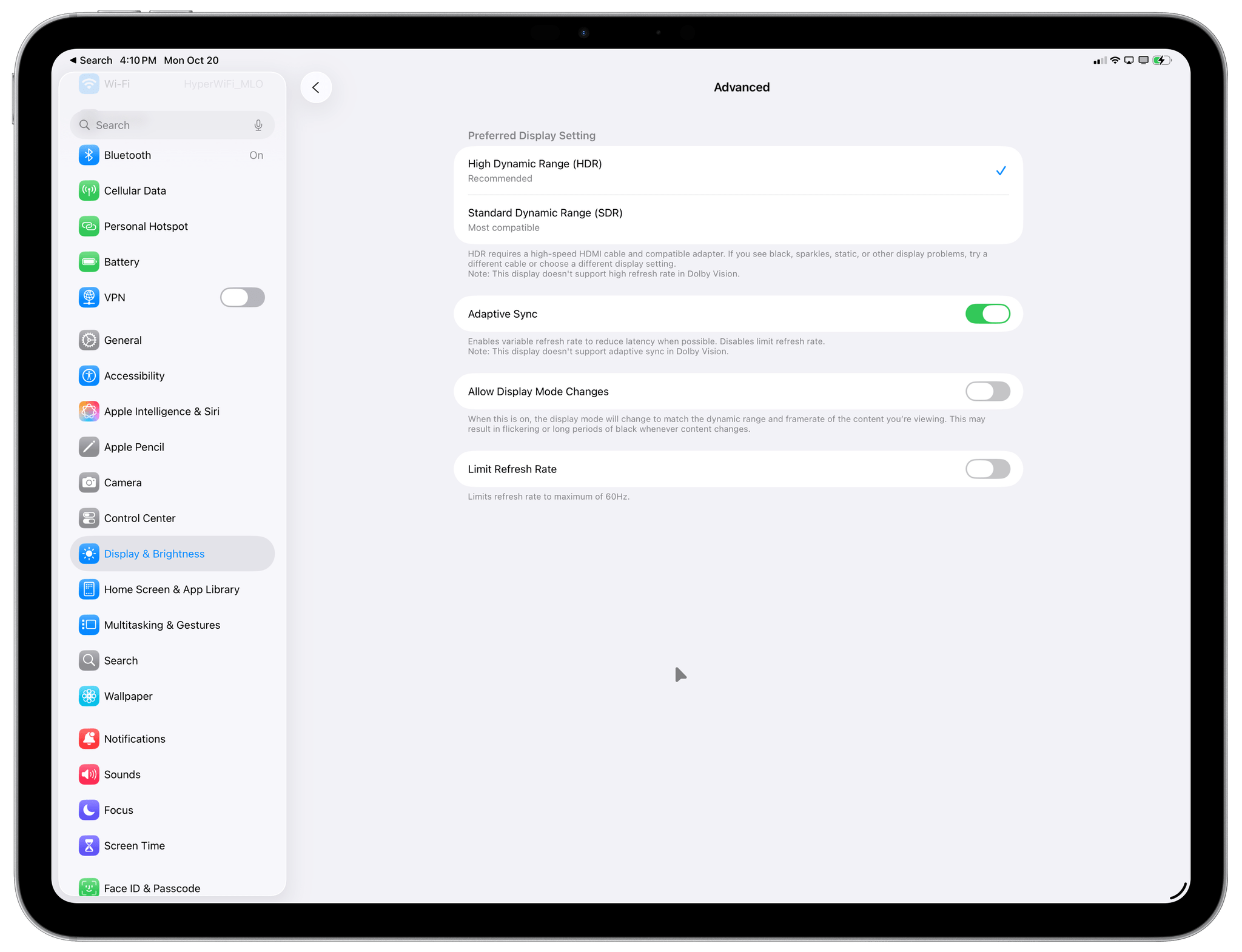
Since, like I mentioned, I’m not playing high-end games on the iPad Pro – let alone competitive games that would benefit from VRR – I’ve chosen to keep Adaptive Sync off and always have my external display refresh at 120Hz. But if you’re the kind of person who plays competitive games on iPadOS and wants to have the best possible experience, I’m guessing you’ll be happy to enable this setting, assuming your monitor allows for it.
As for the other hardware-related features in the iPad Pro, I couldn’t observe any meaningful changes – for better or worse – in Bluetooth 6 or Thread (enabled by the new N1 chip) or cellular connections based on the C1X modem. The latter is, arguably, a good thing: the new modem didn’t perform any better for 5G connections in my area, but it also didn’t perform any worse than its Qualcomm predecessor on the M4 iPad Pro. I consistently got the same 5G speeds across the M4 and M5 iPad Pro in my neighborhood, and I never noticed any particular hiccups with the new modem. It “just worked”, which is also what I’d say about the C1X in my iPhone Air.
An Aspirational Upgrade
In their announcement of the M5 iPad Pro, Apple wrote:
The new iPad Pro features the next generation of Apple silicon, with a big leap in AI performance, faster storage, and the game-changing capabilities of iPadOS 26.
All of this is true, but as I wrap up this review, I want to be realistic here. Who’s buying an iPad Pro for local AI performance today? Who’s buying an iPad Pro for gaming? Where are the first-party Apple apps that tap into this local AI and ray tracing rendering power to demonstrate what is possible with Apple silicon on an iPad Pro?
Ironically, Apple’s marketing strategy for the M5 on the iPad Pro would work a lot better with “one simple trick”: if only they borrowed more aspects of macOS – such as a Terminal app, the ability to install software from the web, or the ability to run more Steam games with a Proton-like compatibility layer – then the M5 iPad Pro’s story would be a lot clearer today.
Instead, the AI “leap” that Apple mentions is true on paper, but pointless in practice if you purchase a new iPad Pro this week and start downloading apps and games from the App Store. You’ll be stuck with the same collection of few AAA game ports and a limited selection of third-party apps to use local LLMs with. And even then, all of those apps will have to download their own third-party models (because the Apple Foundation model simply isn’t good enough for most tasks) with a fragmented ecosystem of models running via llama.cpp or an older version of MLX. It is, quite frankly, a mess.
I have no doubt that, over time, the M5’s narrative for local AI and MLX will come into focus, especially on the Mac. But as things stand today, unless you’re a video editor or really like fast charging and a 120Hz refresh rate on external displays, I wouldn’t recommend upgrading to an M5 iPad Pro over your M4 or, arguably, even M2 iPad Pro.
Apple fixed a lot of issues with iPadOS 26 and its improvements to windowing, audio recording, file management, and more. But if the M5’s focus is on local AI and game rendering, a tale as old as the iPad itself rears its head again: the iPad’s software needs to catch up.