I mentioned this on AppStories during the week of WWDC: I think Apple’s new ‘Use Model’ action in Shortcuts for iOS/iPadOS/macOS 26, which lets you prompt either the local or cloud-based Apple Foundation models, is Apple Intelligence’s best and most exciting new feature for power users this year. This blog post is a way for me to better explain why as well as publicly investigate some aspects of the updated Foundation models that I don’t fully understand yet.
On the surface, the ‘Use Model’ action is pretty simple: you can choose to prompt Apple’s on-device model, the cloud one hosted on Private Cloud Compute, or ChatGPT. You can type whatever you want in the prompt, and you can choose to enable a follow-up mode in the action that lets you have a chatbot-like conversation with the model.
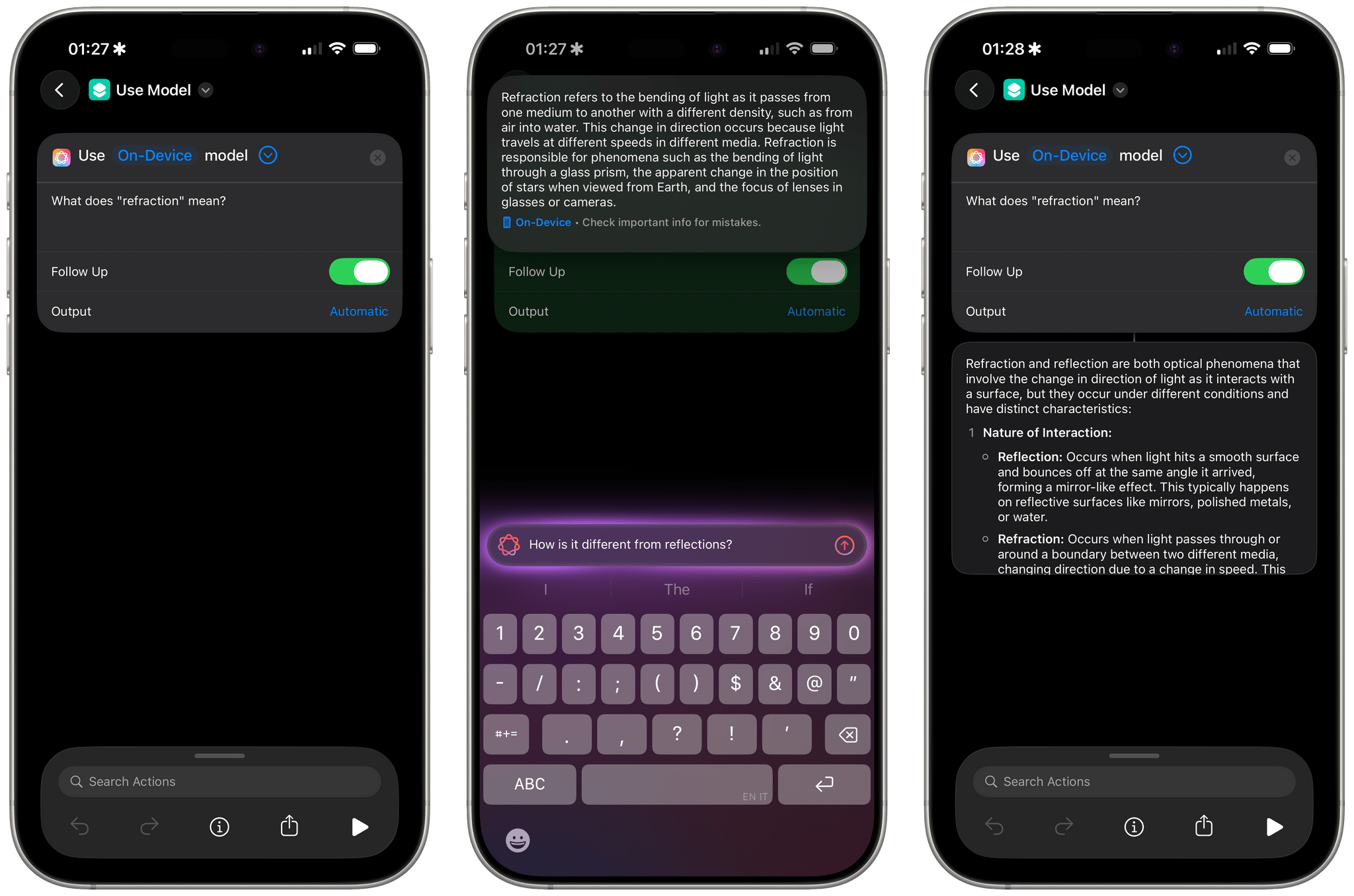
What’s immediately notable here is that, while third-party app developers only got access to the local Foundation model to use in their apps, Shortcuts users can prompt either versions of AFM. It’s not clear if the cloud model is going to be rate-limited if you perform too many requests in a row, which is something I’d like to clarify at some point (but I would expect so). Likewise, while the ChatGPT integration seems to integrate with the native ChatGPT extension in Settings and therefore connects to your OpenAI account, it’s not clear which ChatGPT model is being used at the moment. Trying to ask the model about it from Shortcuts showed that ChatGPT in Shortcuts was using GPT-4 Turbo, which is a very old model at this point (from November 2023).
I want to focus on the Apple Foundation models for now. To understand how they work, let’s first take a look at a recent post from Apple’s Machine Learning Research blog. On June 9, the company shared some details on the updated Foundation models, writing:
The models have improved tool-use and reasoning capabilities, understand image and text inputs, are faster and more efficient, and are designed to support 15 languages. Our latest foundation models are optimized to run efficiently on Apple silicon, and include a compact, approximately 3-billion-parameter model, alongside a mixture-of-experts server-based model with a novel architecture tailored for Private Cloud Compute. These two foundation models are part of a larger family of generative models created by Apple to support our users.
Both Foundation models were originally released last year. Apple doesn’t explicitly mention whether the ‘Use Model’ action in Shortcuts is currently using the updated versions of AFM compared to last year’s versions, but I would assume so? Again, I’d love to know more about this. Assuming that the answer is “yes”, we’re then looking at a small, ~3B model running locally on-device, and a bigger, cloud-hosted model (previously referred to as “AFM-server”) running on Private Cloud Compute. How big is exactly that model, though? Again, let’s go back to the blog post:
We found that our on-device model performs favorably against the slightly larger Qwen-2.5-3B across all languages and is competitive against the larger Qwen-3-4B and Gemma-3-4B in English. Our server-based model performs favorably against Llama-4-Scout, whose total size and active number of parameters are comparable to our server model, but is behind larger models such as Qwen-3-235B and the proprietary GPT-4o.
If Llama-4-Scout is “comparable” to AFM-server, we may assume that the updated AFM-server based on a MoE architecture is ~17 billion in size. Apple hasn’t officially documented this anywhere. Still, as a frame of reference, Apple is saying that their server model isn’t as good as modern ChatGPT or the latest large Qwen 3 model. But perhaps internally they do have one that matches the current version of ChatGPT in quality and performance?
Another aspect of the updated Apple Foundation models I’d like to understand are their vision capabilities. On its blog, Apple writes:
We compared the on-device model to vision models of similar size, namely InternVL-2.5-4B, Qwen-2.5-VL-3B-Instruct, and Gemma-3-4B, and our server model to Llama-4-Scout, Qwen-2.5-VL-32B, and GPT–4o. We found that Apple’s on-device model performs favorably against the larger InternVL and Qwen and competitively against Gemma, and our server model outperforms Qwen-2.5-VL, at less than half the inference FLOPS, but is behind Llama-4-Scout and GPT–4o.
The problem is that, right now, trying to analyze an image using the local model with the ‘Use Model’ action in Shortcuts doesn’t work. When I give it this image, I get this response:
I’m sorry, but I can’t describe images directly. However, if you provide a detailed description or tell me what you see, I’d be happy to help you analyze or interpret it!
Whereas running the same prompt with the cloud model returns a pretty good response:
The image shows a person walking two dogs on a paved path. The person is wearing white sneakers and is holding two leashes, one pink and one purple. The dogs are walking side by side, both with light brown fur and wearing harnesses. The path is lined with grass and some small plants on the left side. The scene appears to be outdoors, possibly in a park or a residential area. The lighting suggests it might be daytime.
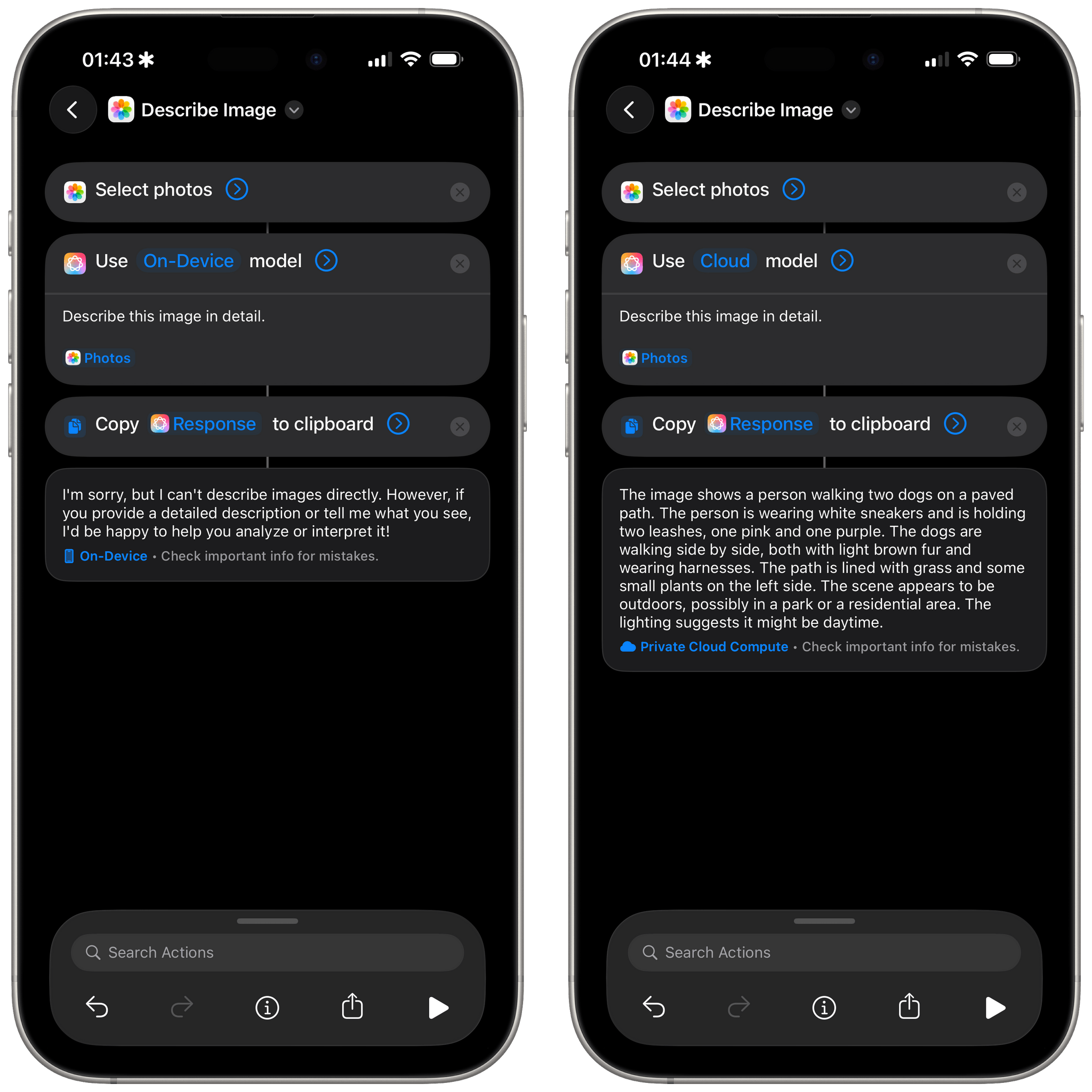
Does this mean that Shortcuts is still using an old version of the on-device model, which didn’t have vision capabilities? Or is it the new model from 2025, but the vision features haven’t been enabled in Shortcuts yet? Also: why is it that, if I give the cloud model the same picture over and over, I always get the exact same response, even after several days? Is Apple caching a static copy of each uploaded file on its servers for days and associating it with a specific description to decrease latency and inference costs? Again: has this been documented anywhere? Please let me know if so.
The most fascinating part of the ‘Use Model’ action is that it works with structured data and is able to directly parse native Shortcuts entities as well as return specific data types upon configuration. For example, you can tell the ‘Use Model’ action to return a ‘Dictionary’ for your prompt, and the model’s response will be a native dictionary type in Shortcuts that you can parse with the app’s built-in actions. Or you can choose to return text, lists, and Boolean values.
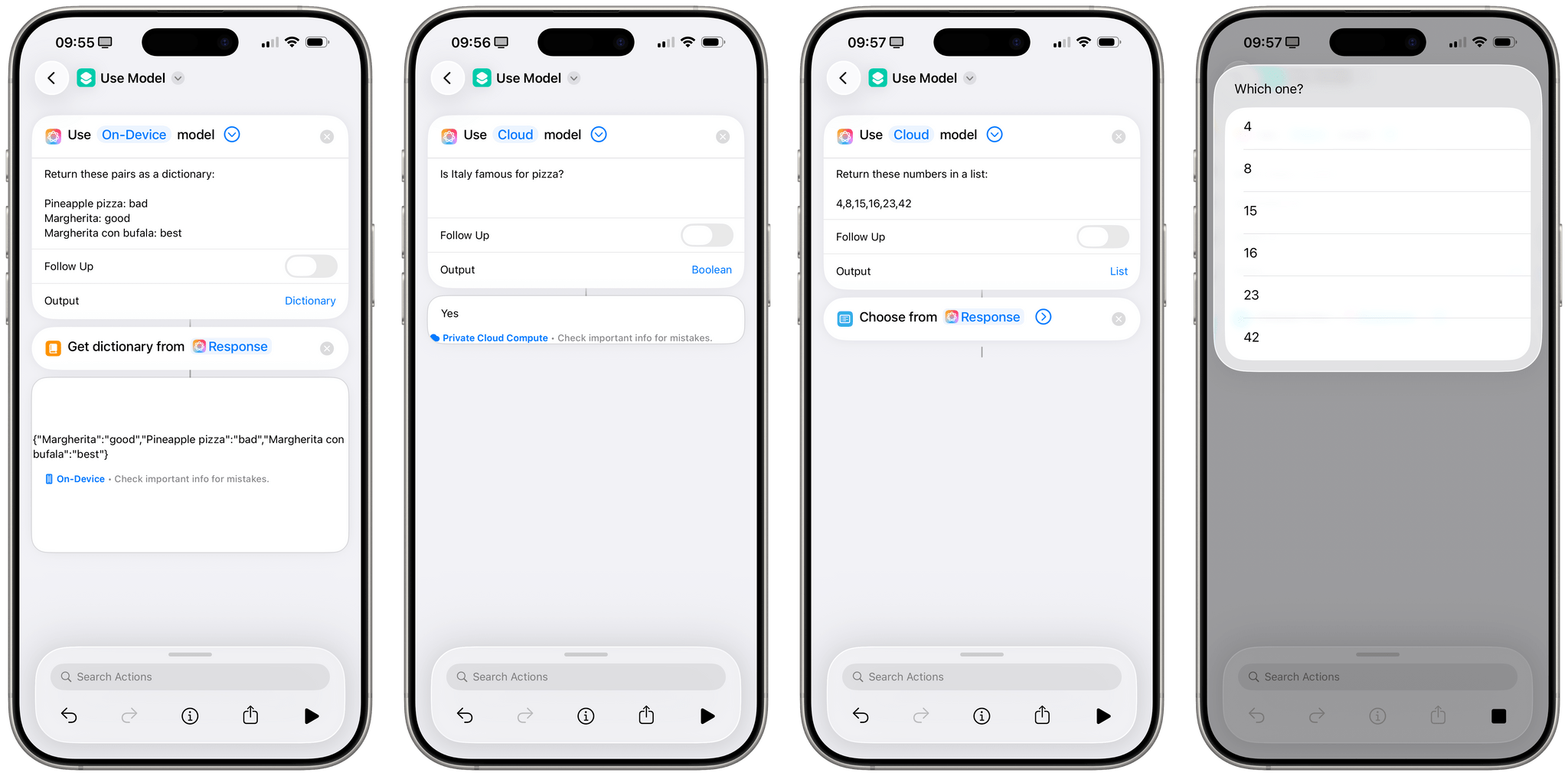
But there’s more: the ‘Use Model’ action can take in Shortcuts variables, understand them, and return them in its output, going beyond the typical limitations of plain text responses from chatbots. From the official description of the ‘Use Model’ action:
A request for the model that optionally includes variables and outputs from previous actions, including calendar events, reminders, photos, and more.
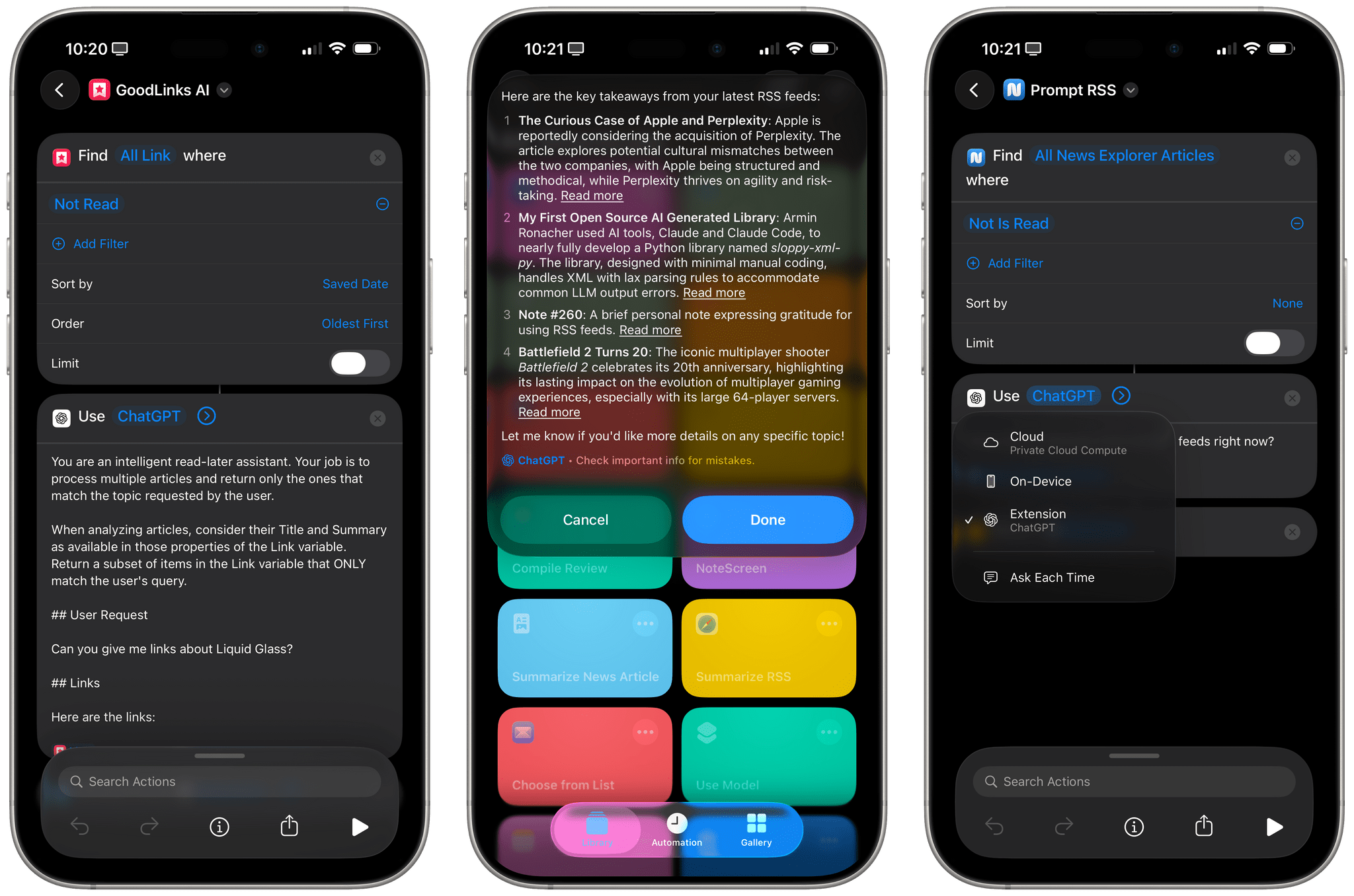
The “and more” is doing a lot of work here, in the sense that, based on my first tests, this action seems to be able to parse any Shortcuts variable you give it. I put together a simple shortcut that gets all my unread items from GoodLinks and asks the local model:
You are an intelligent read-later assistant. Your job is to process multiple articles and return only the ones that match the topic requested by the user.
When analyzing articles, consider their Title and Summary as available in those properties of the Link variable. Return a subset of items in the Link variable that ONLY match the user’s query.
User Request
Can you give me links about Liquid Glass?
Links
Here are the links:
{{Link Variable from GoodLinks}}
Once configured to return a ‘Link’ type in its output, the action can parse GoodLinks entities (which contain multiple pieces of metadata about each saved article), filter the ones that don’t match my query, and return a native list of GoodLinks items about Liquid Glass:
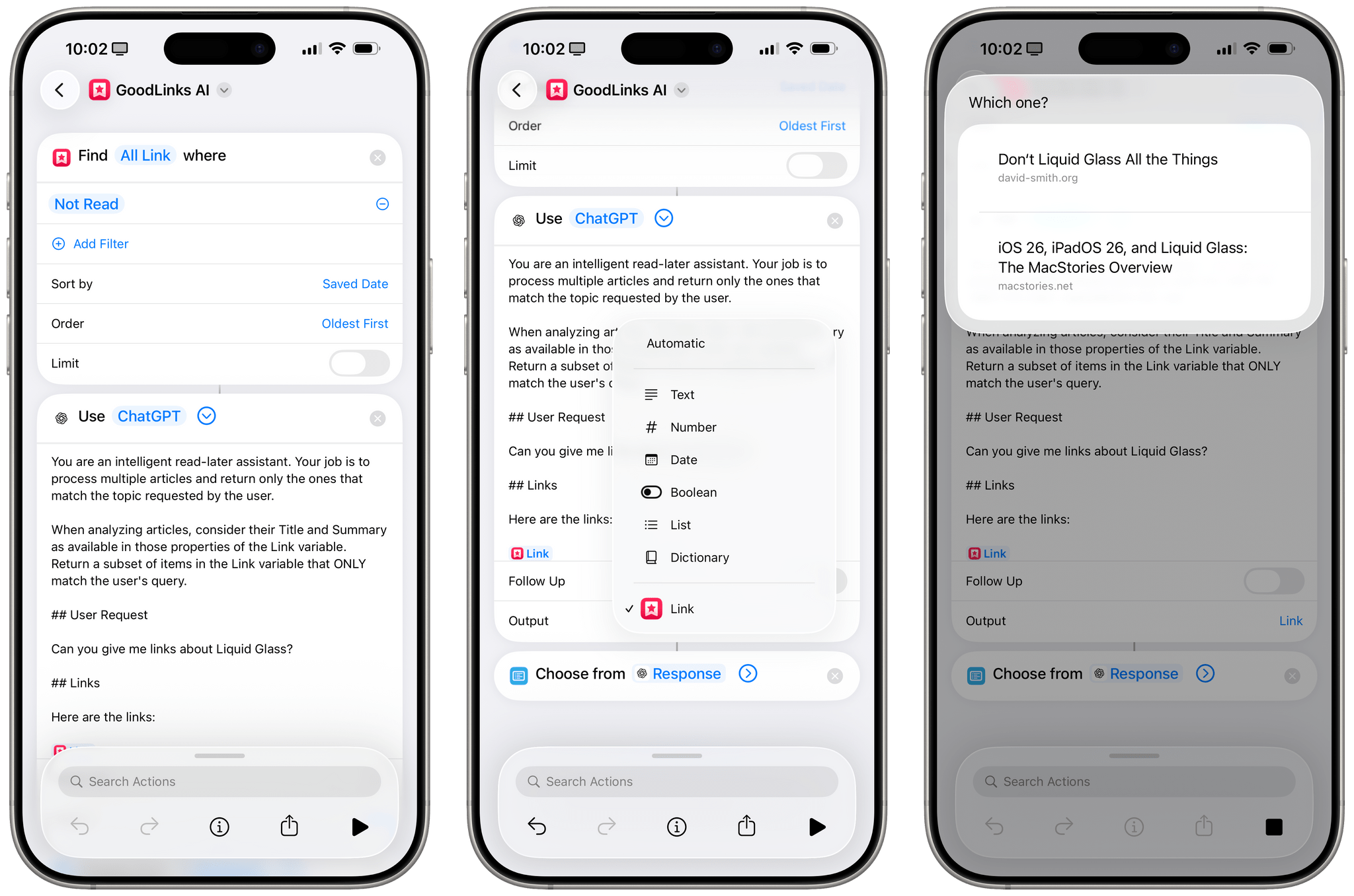
This also works with Reminders, Calendar events, photos, and other third-party apps I’ve tested. For example, the model was also able to return variables for News Explorer, an iCloud-based RSS reader that has excellent Shortcuts integration. Interestingly, neither Apple Intelligence models were able to parse 43 unread items in my RSS feeds, citing context length issues. This is something else I’d like to know: Apple’s blog post suggests that AFM was trained with prompts up to 65K tokens in size, but is that actually the case in Shortcuts with the ‘Use Model’ action? Regardless, ChatGPT got it done and was able to summarize all my unread items from News Explorer to give me an overview of what my unread feeds were saying:
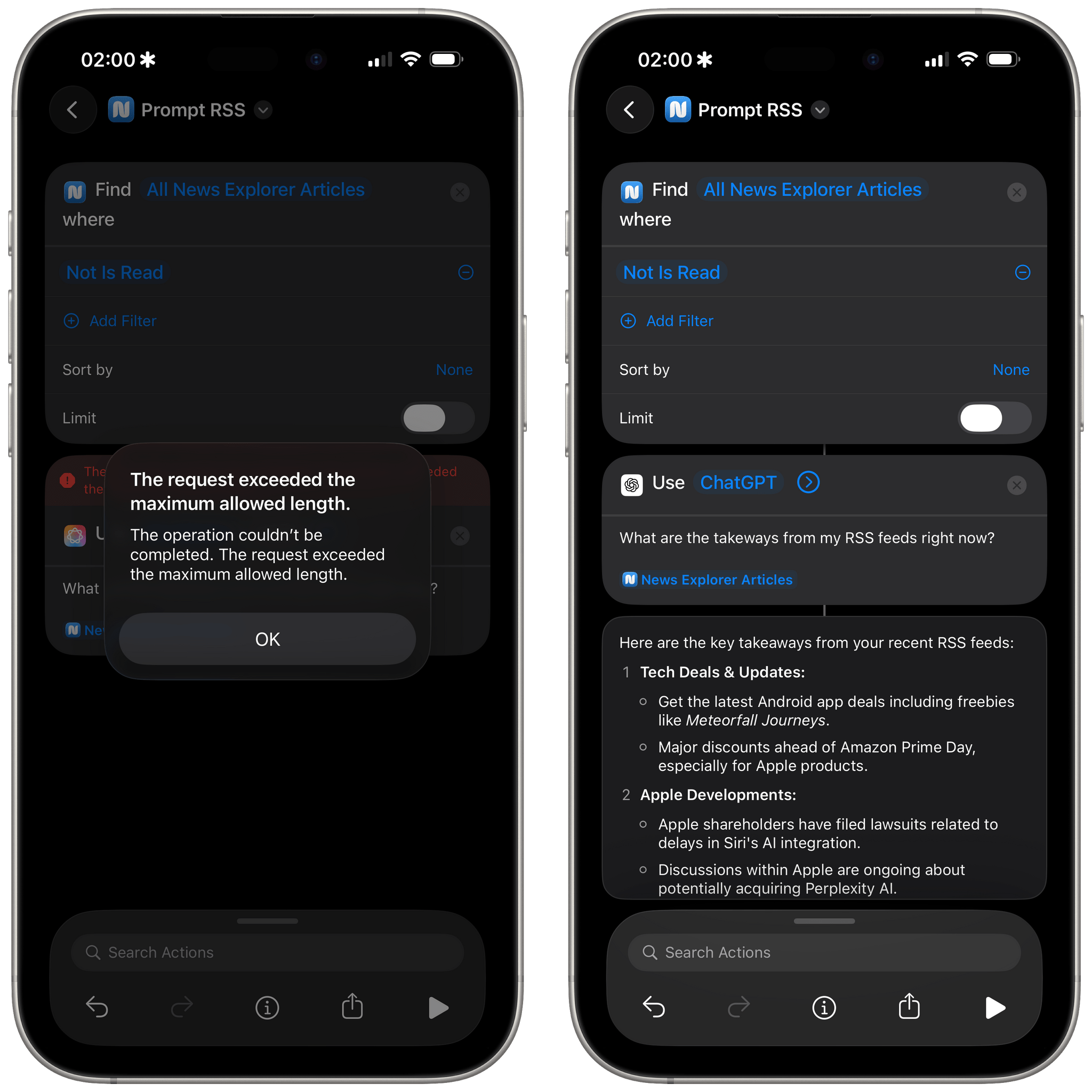
AFM couldn’t process my 43 unread items from RSS, but ChatGPT could, likely thanks to its bigger 128K context window.
How is this possible? We do actually have an answer to this! The ‘Use Model’ action converts Shortcuts entities from apps (such as my GoodLinks articles or reminders) into a JSON representation that AFM or ChatGPT can understand and return. Everything is, of course, based on the App Intents framework and its related app entities for third-party apps that expose actions to Shortcuts.
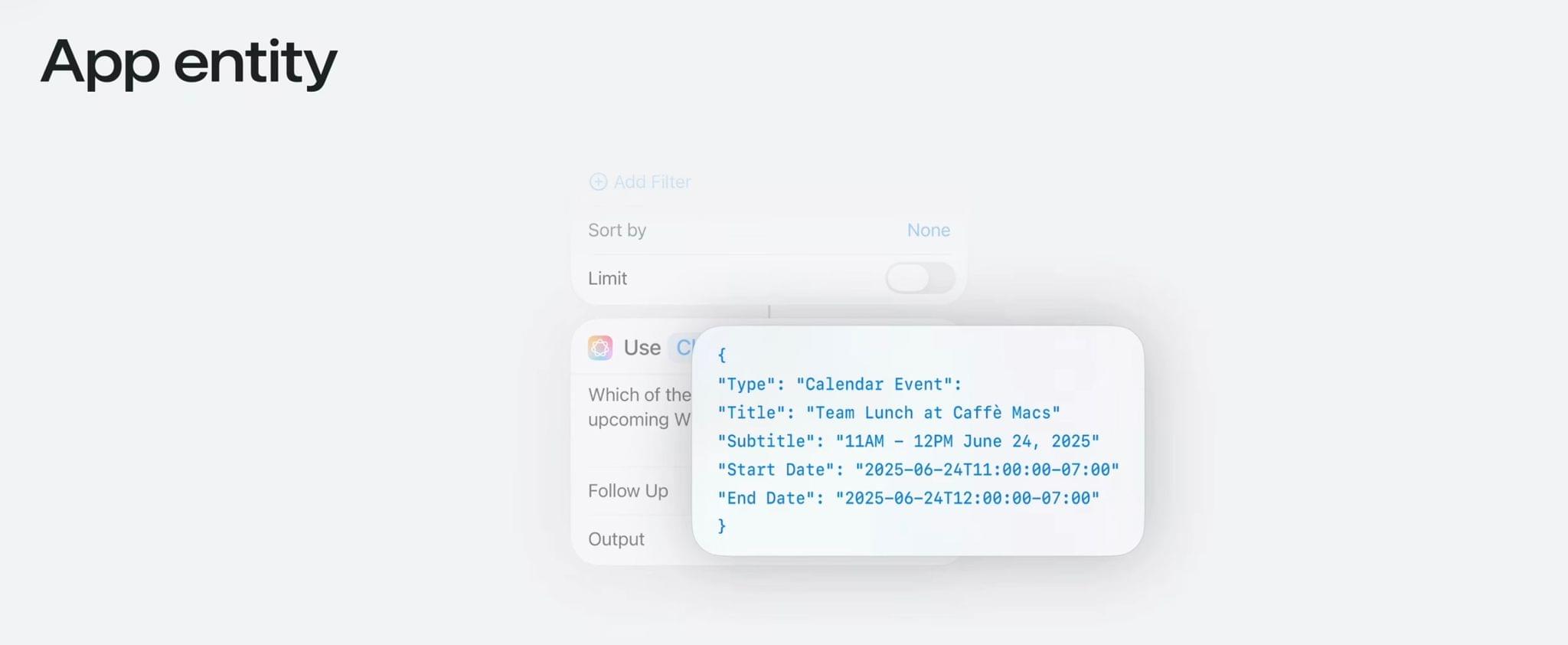
If you’re logged in with a ChatGPT account, you can even see the request and the raw JSON content coming from Shortcuts:
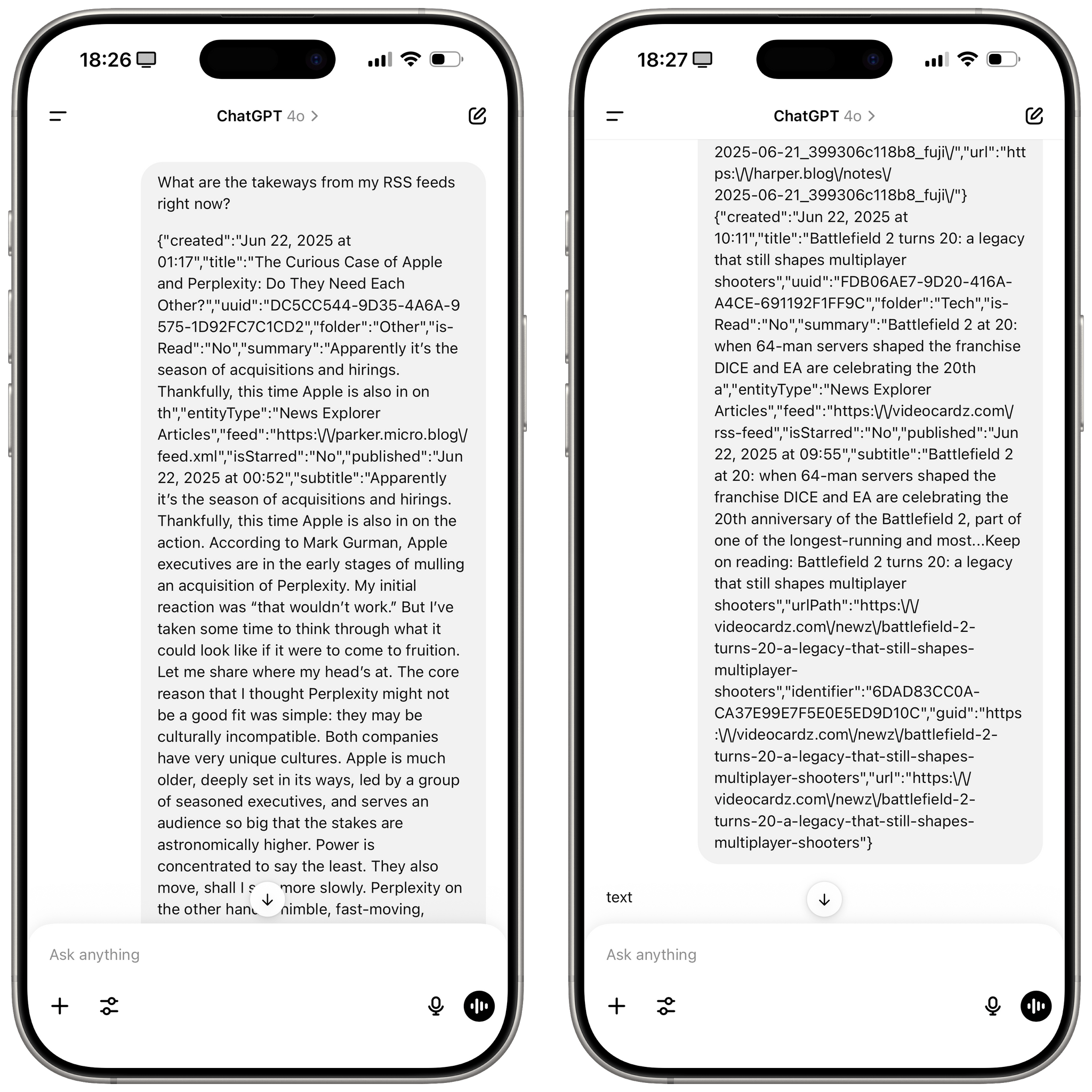
{kind=link}
Apple went into more detail about how this works in this WWDC session video, which I’m also embedding below. The relevant section starts at the 1:20 minute mark.
Again, I’d love to know some additional details here: are there limits on the numbers of entities converted to JSON behind the scenes that you can pass to a model? Can this JSON-based approach easily scale to more potential Apple Intelligence model integrations in the future, since both Gemini and Claude are pretty great at dealing with JSON content and instruction-following? Is there a specific style of prompting Apple’s Foundation models (similar to Claude or GPT 4.1) that we should be aware of?
I’d love to see the system prompt that injects JSON and related instructions into the main action prompt, but I’m guessing that’s never going to happen since Apple doesn’t seem to be interested in sharing system prompts for Apple Intelligence.
I’m excited about the prospect of “Apple-approved” hybrid automation in Shortcuts that combines the non-deterministic output of LLMs with the traditional, top-to-bottom approach of workflows in Shortcuts. I have so many ideas for how I could integrate this kind of technology with shortcuts that deal with RSS, tasks, events, articles, and more. The fact that Apple designed the ‘Use Model’ action to “just work” thanks to JSON under the hood is very promising: as I’ve shown in my example, it means that entities from Shortcuts actions don’t have to belong to apps that have been updated for iOS 26; I’m running the iOS 18 version of GoodLinks, and the ‘Use Model’ action worked out of the box with GoodLinks entities.
Hopefully, as the dust settles on the first developer betas of iOS/iPadOS/macOS 26, Apple will reveal more details about their Foundation models and their integration with Shortcuts. Who would have thought, just two weeks ago, that I’d be genuinely intrigued by something related to Apple Intelligence?