The best kind of follow-up article isn’t one that clarifies a topic that someone got wrong (although I do love that, especially when that “someone” isn’t me); it’s one that provides more context to a story that was incomplete. My M5 iPad Pro review was an incomplete narrative. As you may recall, I was unable to test Apple’s promised claims of 3.5× improvements for local AI processing thanks to the new Neural Accelerators built into the M5’s GPU. It’s not that I didn’t believe Apple’s numbers. I simply couldn’t test them myself due to the early nature of the software and the timing of my embargo.
Well, I was finally able to test local AI performance with a pre-release version of MLX optimized for M5, and let me tell you: not only is the hype real, but the numbers I got from my extensive tests over the past two weeks actually exceed Apple’s claims.
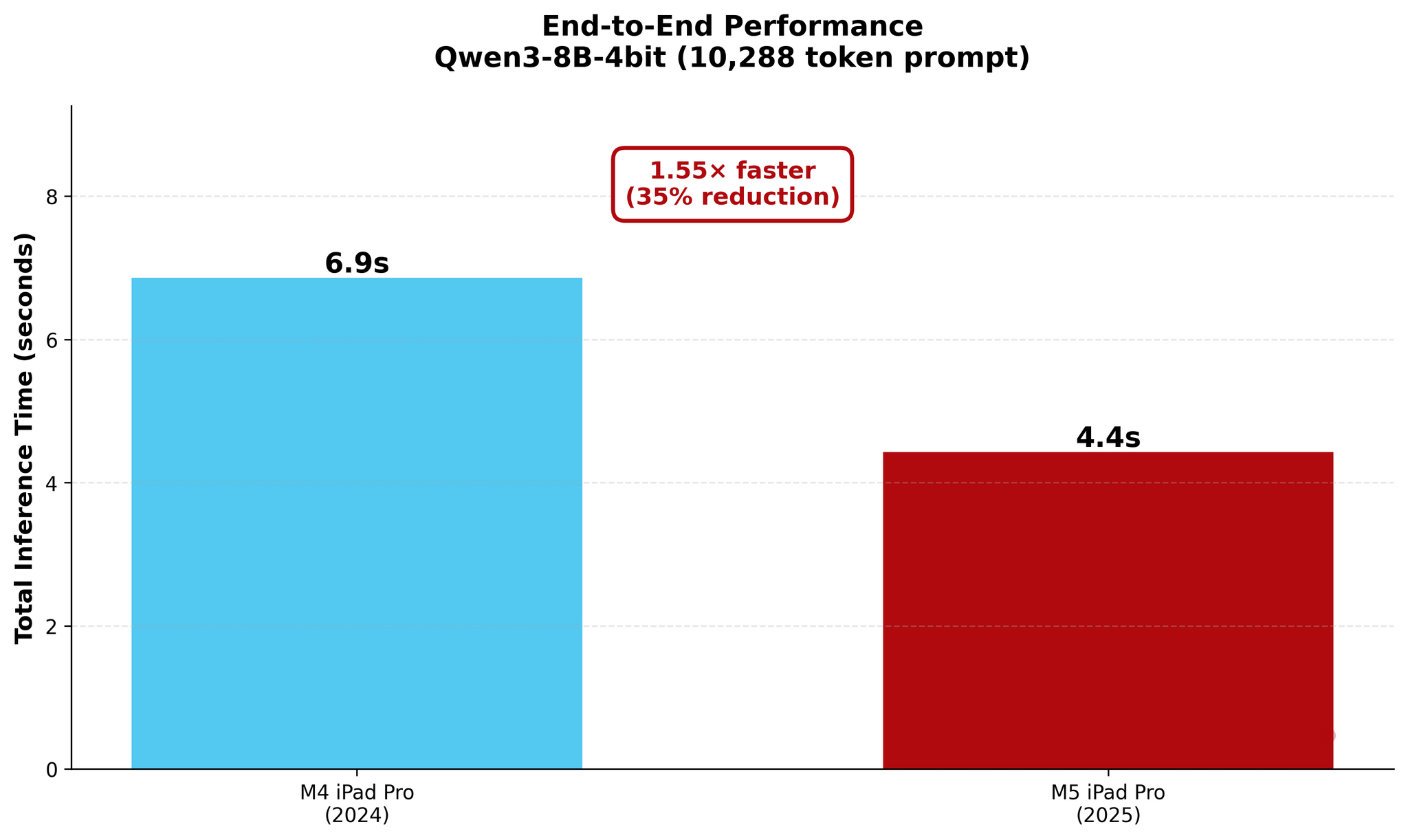
This article won’t be long, and I’ll let the charts I recreated for the occasion speak for themselves. Essentially, as I suggested in my iPad Pro review, the M5’s improvements for local AI performance largely apply to prompt processing (the prefill stage, when an LLM needs to ingest the user’s prompt and load it into its context) and result in much, much shorter time to first token (TTFT) numbers. Since prompt processing with neural acceleration scales better with long prompts (where you can more easily measure the difference in latency between the M4 and M5), I focused on testing two different long prompt sizes: 10,000 and 16,000 tokens.
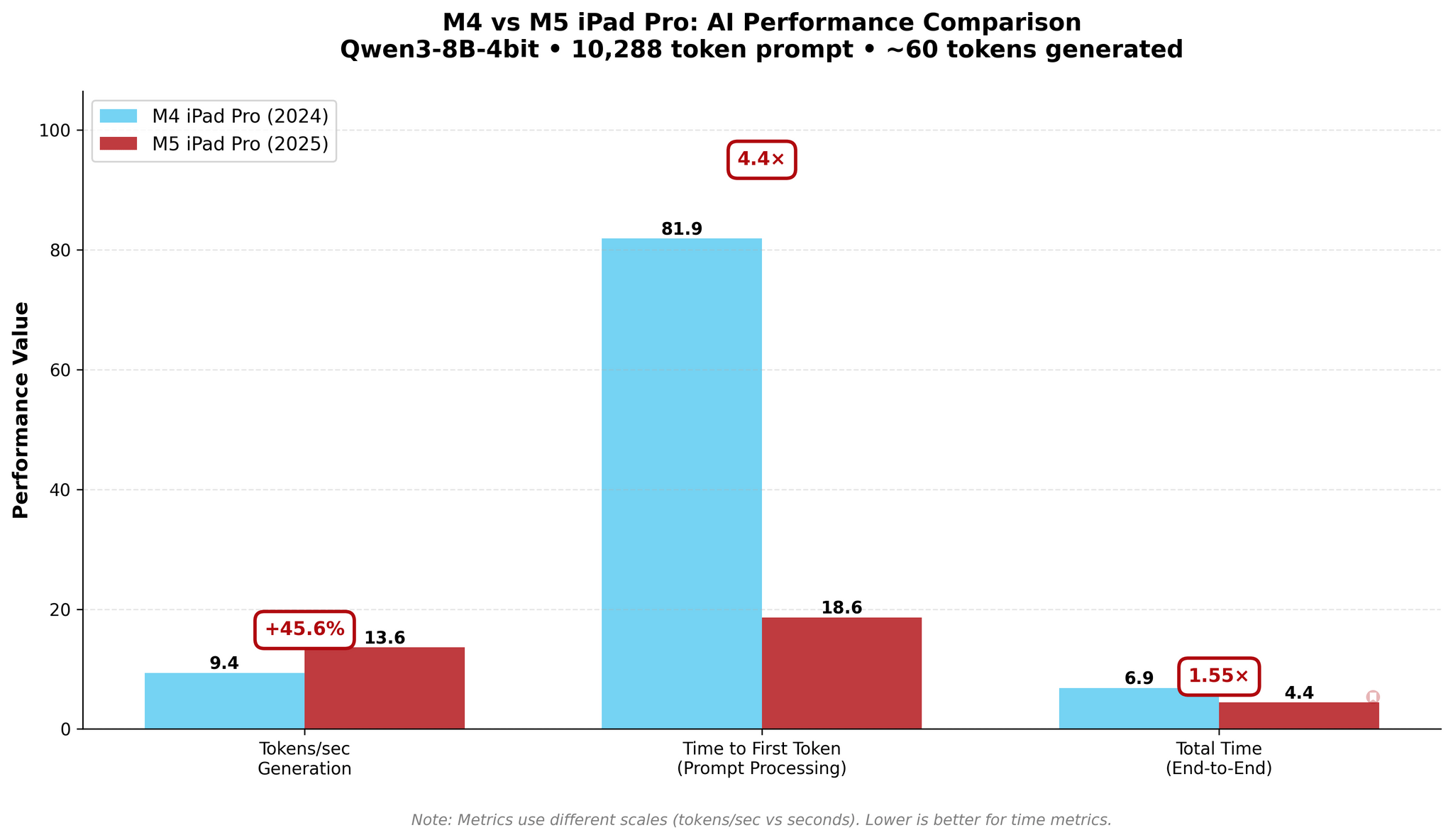
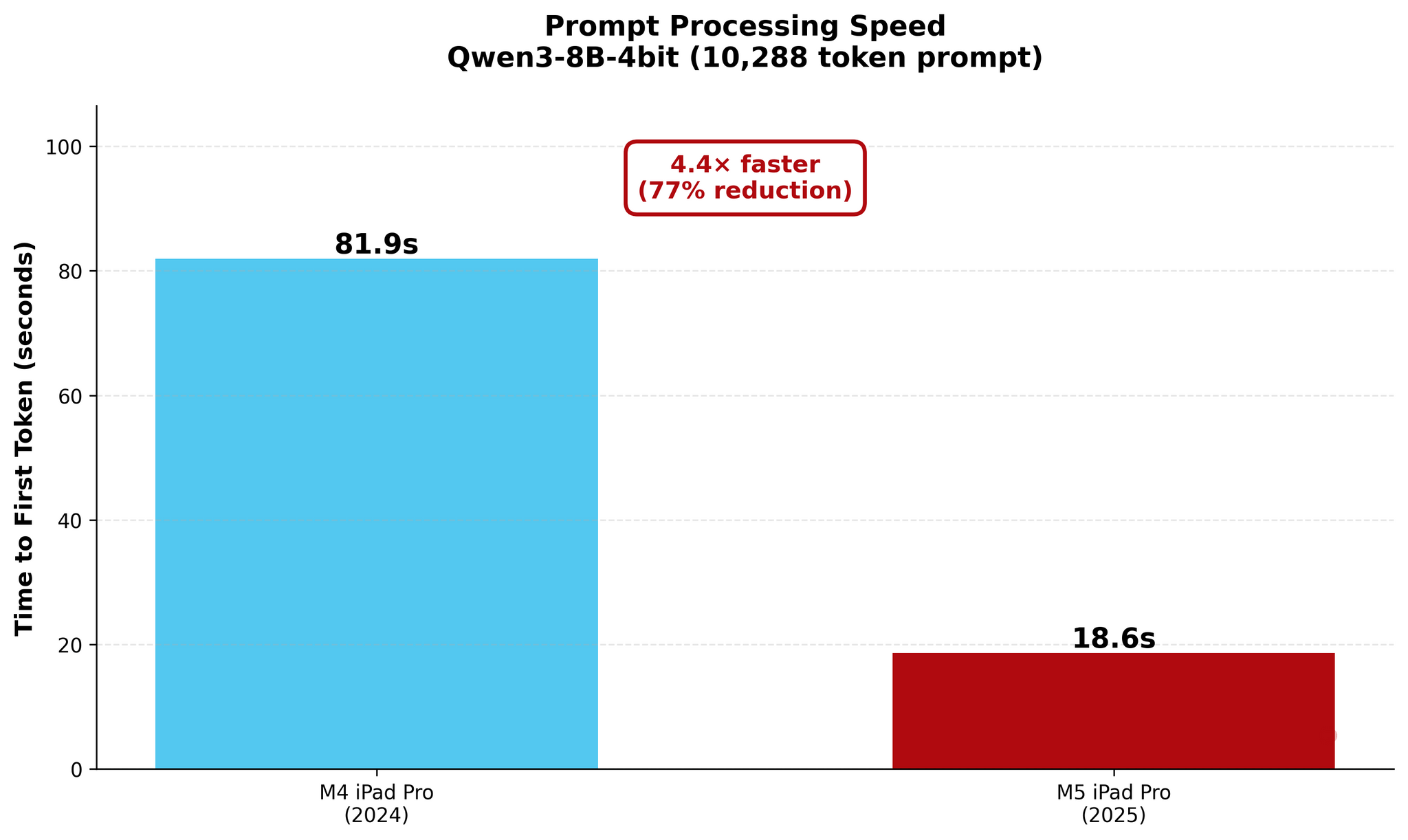
In my new tests based on an updated version of one of the published MLX samples, I used Qwen3-8B-4bit to measure the performance of local AI on my old M4 iPad Pro and new M5 iPad Pro. As you will see in the charts below, a prompt that took the M4 81 seconds to process was loaded by the M5 in 18 seconds – a 4.4× improvement in TTFT. The numbers become even more impressive with longer prompts: while it took the M4 118 seconds (nearly two minutes!) to start generating an answer for a 16,000-token prompt, the M5 did it…in 38 seconds.
But enough paragraphs about numbers! Let’s see some pretty charts instead.
10k Prompt
16k Prompt
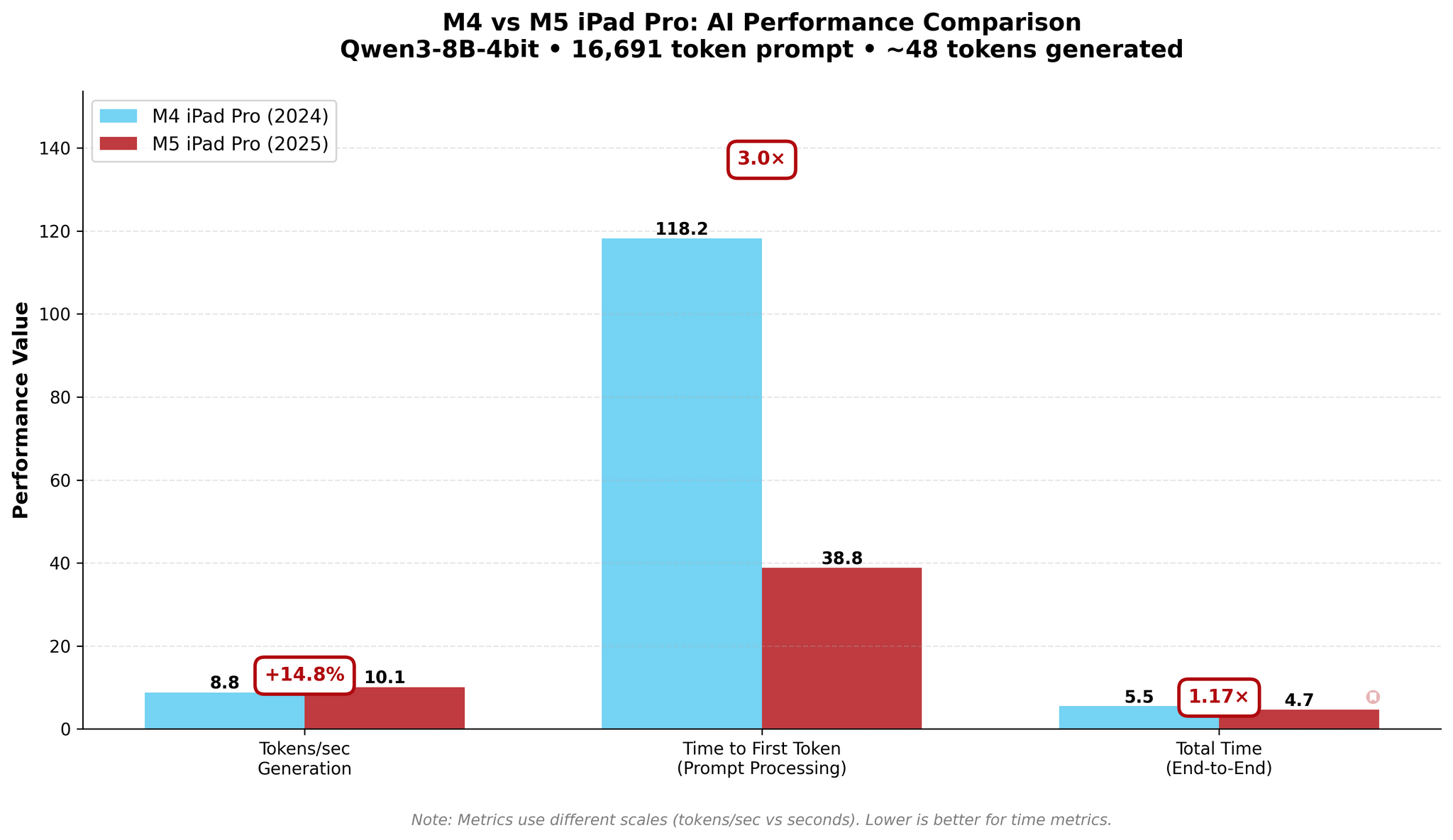
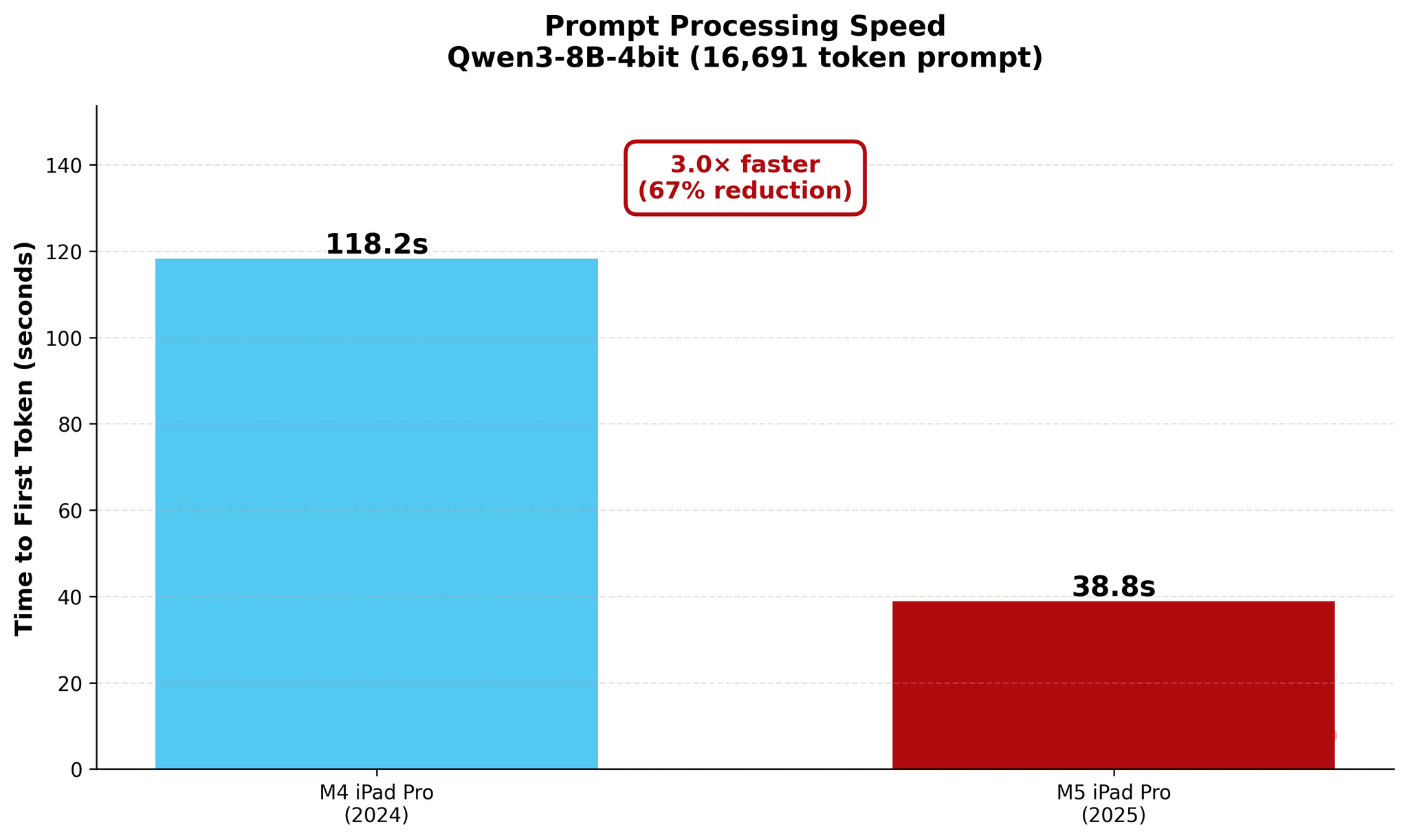
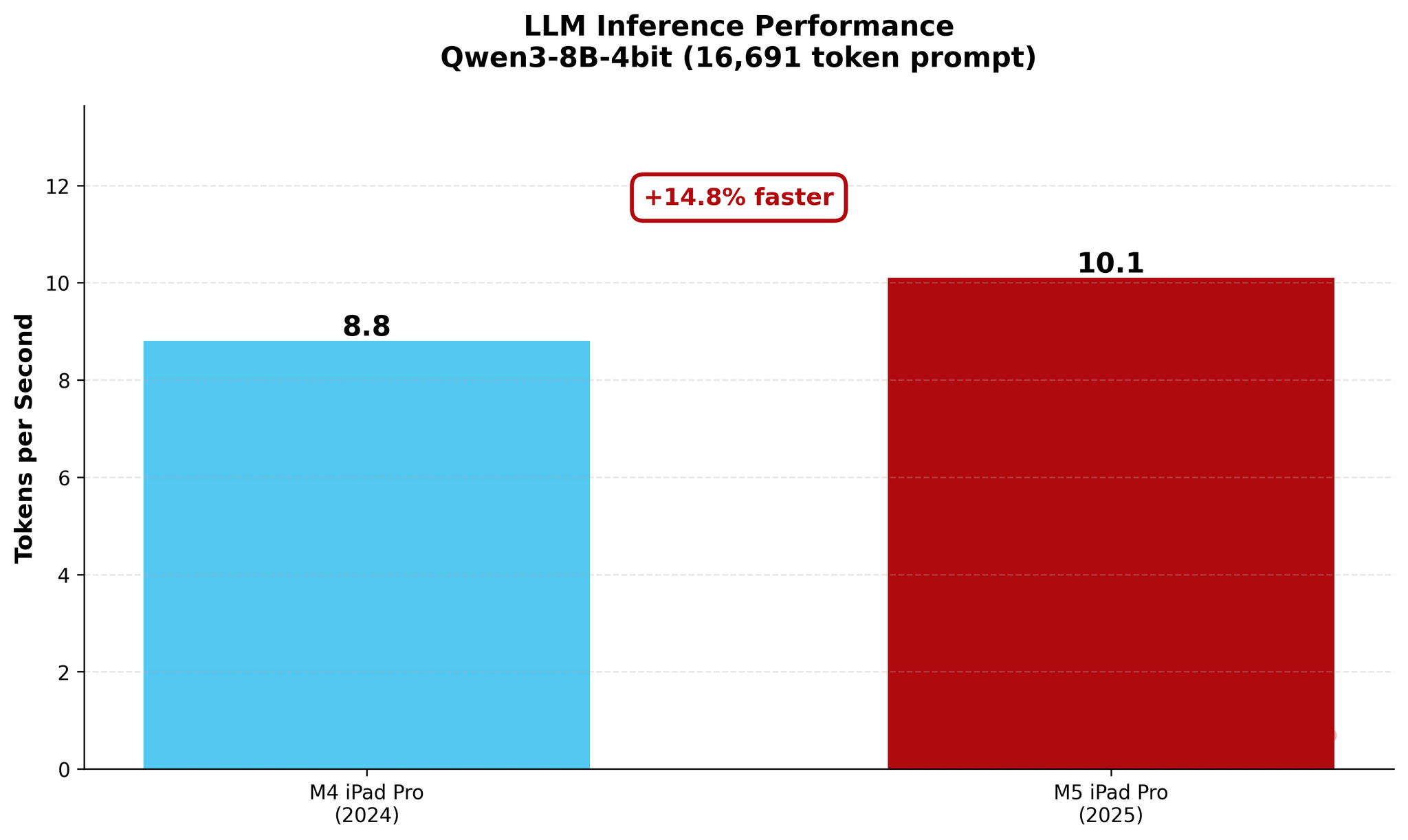
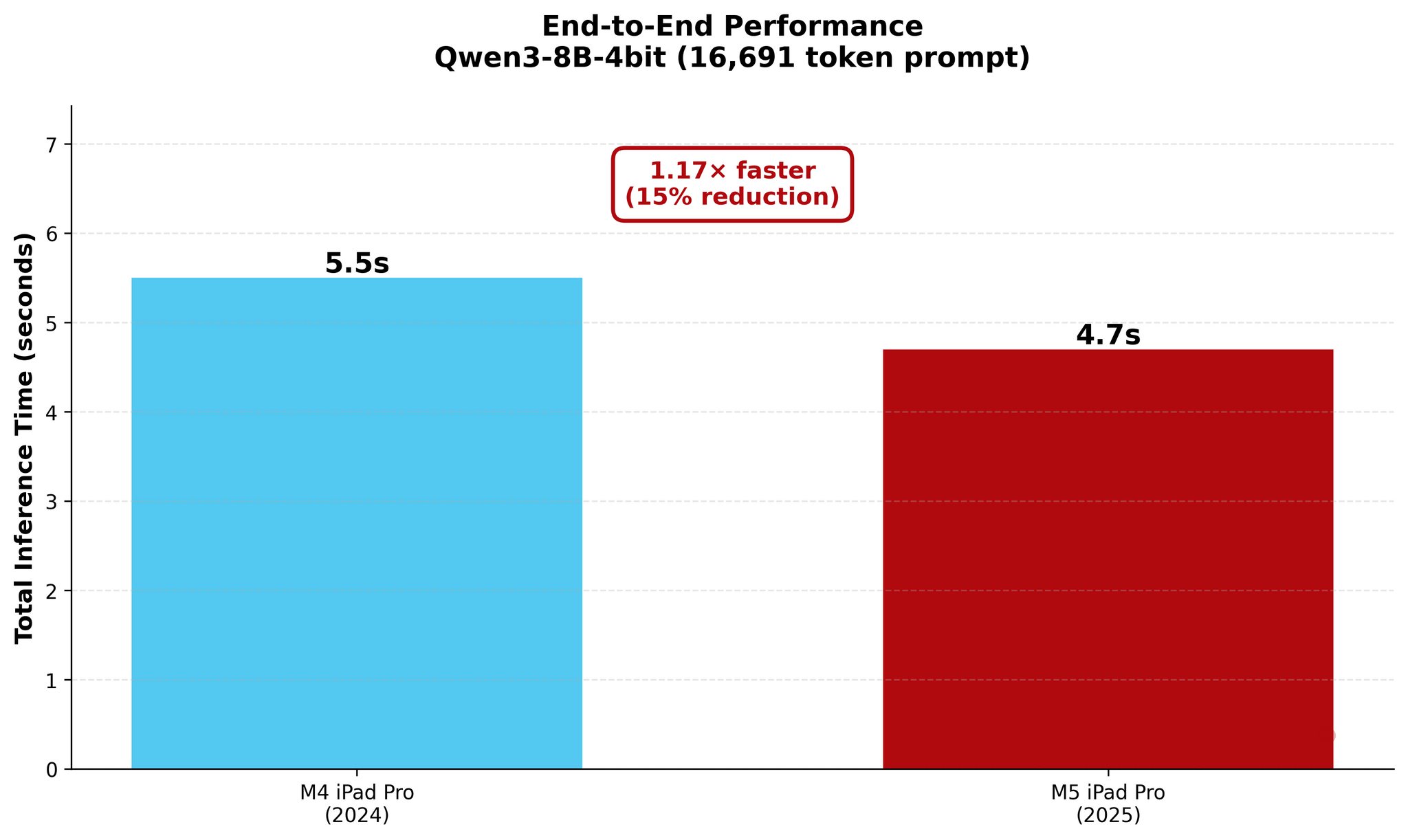
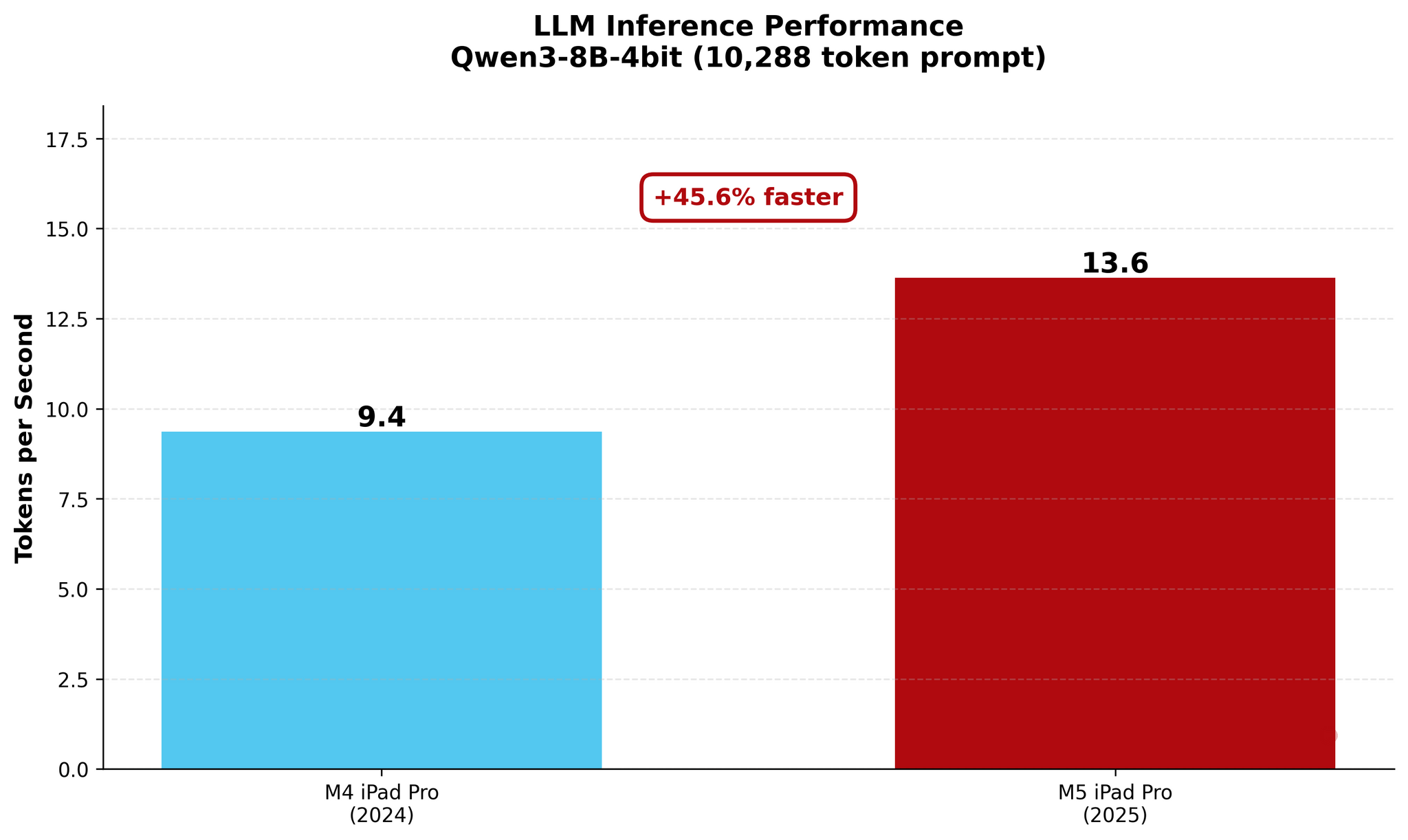
As you can see, there are some improvements for token generation across the M4 and M5, but at 1.5× faster generation, they’re marginal. The star of the show for the M5 is prompt processing in the prefill stage: the Neural Accelerators vastly reduce the time needed by the M5 to process long prompts and start generating answers. The fact that this is happening on a consumer-grade tablet that is thin, lightweight, and fanless is all the more impressive.
In practice, this means a few things.
If you’re a developer of local AI apps for iPad, I highly recommend you start integrating with MLX and consider features that will take advantage of long prompts. RAG applications for cross-document search, LLM clients with “project” features that support system-level instructions, and local AI clients that integrate with MCP servers (MCP tools notoriously fill the context window of LLMs with instructions and tool descriptions) are the kinds of apps that will benefit from the M5’s faster prompt processing the most, especially at long contexts.
For users, although the iPad’s app ecosystem for local AI remains largely aspirational right now and behind the curve compared to macOS, there are early signs of iPad apps that will take advantage of the power of the M5. Apps like Locally AI, OfflineLLM, and Craft (which supports local, offline assistants on iOS and iPadOS) should, theoretically, be able to tap into the power of the M5 and provide considerable performance gains compared to the M4.
The M5 alone doesn’t change the fact that local AI is a niche, and local AI on iPadOS is a niche of a niche right now. However, the power is there, and as soon as the public version of MLX receives support for neural acceleration, we may start seeing a progressive buildup of AI tablet apps that can run offline – and inherently more private – LLMs with the kind of performance that was previously exclusive to desktops.
With this kind of power, it’d be a shame if no one took advantage of it. I hope some third-party iPad app developers will, and I’ll be along for the ride.