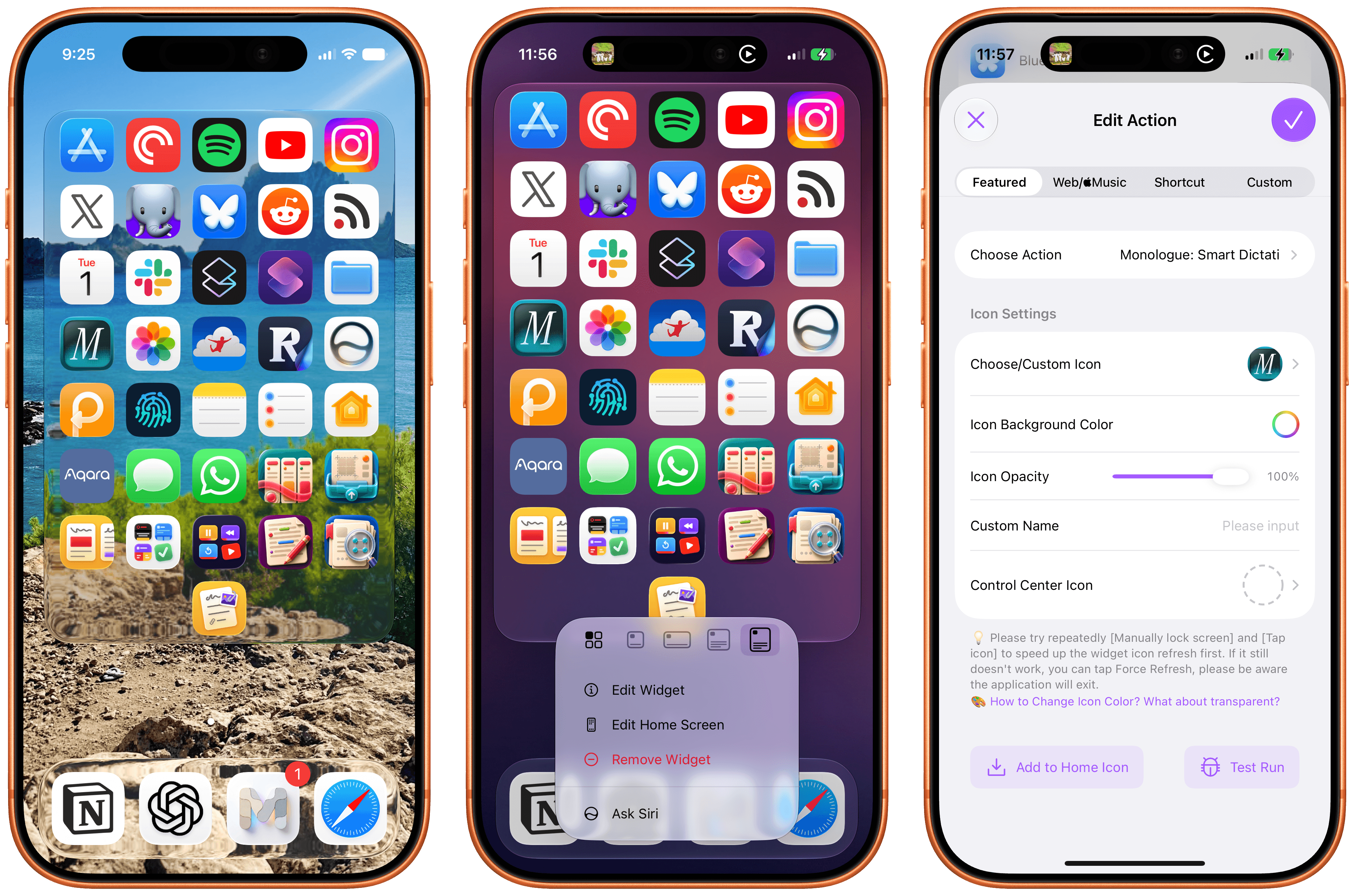
I don’t think I ever mentioned it on MacStories (although I probably did at some point on AppStories or Unwind), but my favorite “launcher” app for iOS is a utility called Lock Launcher, which I’ve been using on and off for the last couple of years. Lock Launcher started as an app for adding URL schemes to the Lock Screen a few years back, and it gradually evolved into a comprehensive “widget studio” app to design launcher widgets of all kinds for the Home Screen, Lock Screen, Dynamic Island, Live Activities, and more.
Anyway, I’m covering the app on the site today because it was updated with two features that I didn’t think were possible or allowed on the App Store, and I want to highlight them for our readers. I’m not really sure how the developers were able to add these features to the app; you may want to download it from the App Store quickly, just in case.
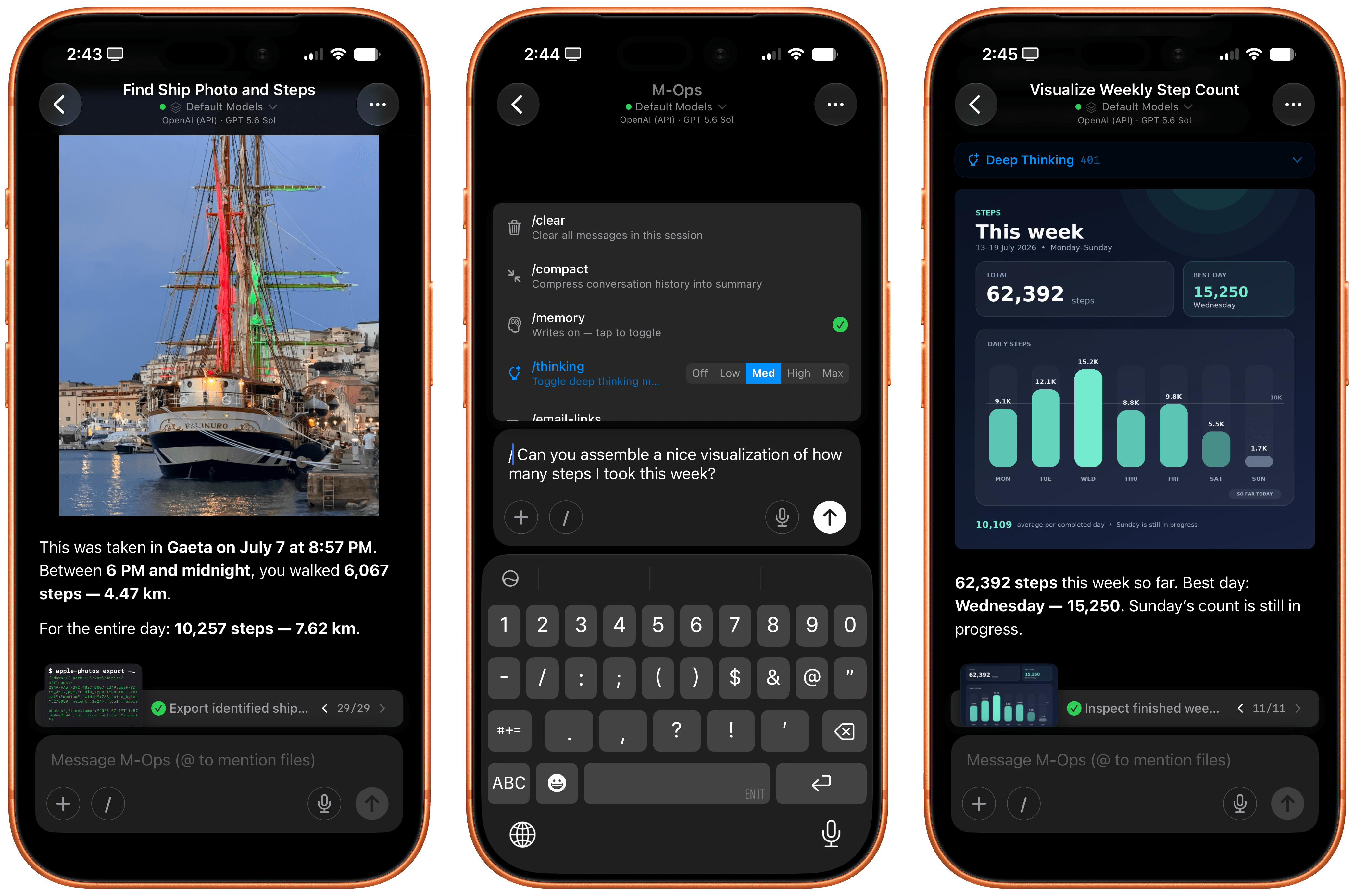
For starters, Lock Launcher now lets you create launcher shortcuts that open apps directly and immediately, rather than redirecting you to the Lock Launcher app first.
For years now, launcher apps on the iPhone have had to employ this workaround: you’d tap on a shortcut that opened, say, Ivory, but you would see the launcher app flash onscreen briefly before redirecting you to the actual destination app you selected. Somehow, Lock Launcher is now circumventing this limitation with a ‘Direct Open’ mode that I haven’t seen in other launcher apps for iOS. That sequence of widget, host app, and destination app was, ultimately, the reason why I always stopped using third-party launcher apps, and I love that it’s been removed by Lock Launcher.
Launching apps without redirects via Lock Launcher.Replay
At long last, I’ve been able to create a dense Home Screen with 40 icons (36 in the widget plus 4 in the dock), and they all launch directly when tapped.

The screenshot above brings me to the second feature added in the version of Lock Launcher currently available on the App Store: XL widgets on iPhone in iOS 27.
Now, as far as I know, if an app wants to adopt an API exclusive to a future version of iOS, it typically needs to be built against that version’s SDK using the corresponding Xcode beta. However, the App Store isn’t currently accepting apps built with the iOS 27 SDK. And yet, the Lock Launcher developers must have figured out a way to support the new systemExtraLargePortrait widget size and make it work on devices running iOS 27 even though the app was built with the iOS 26 SDK. My best guess: they’re using a workaround that involves visionOS 26 APIs, since the Vision Pro received support for that family of widgets last year. (I’d love to know more about this.)
These two features, combined with the ability to apply the Liquid Glass material to widgets for beautiful refractions of the system wallpaper, make Lock Launcher the most powerful and customizable launcher utility on iOS to date. I hope writing about it doesn’t get the developers in trouble.
Lock Launcher is available for free on the App Store, with advanced features available through an optional Pro in-app purchase.