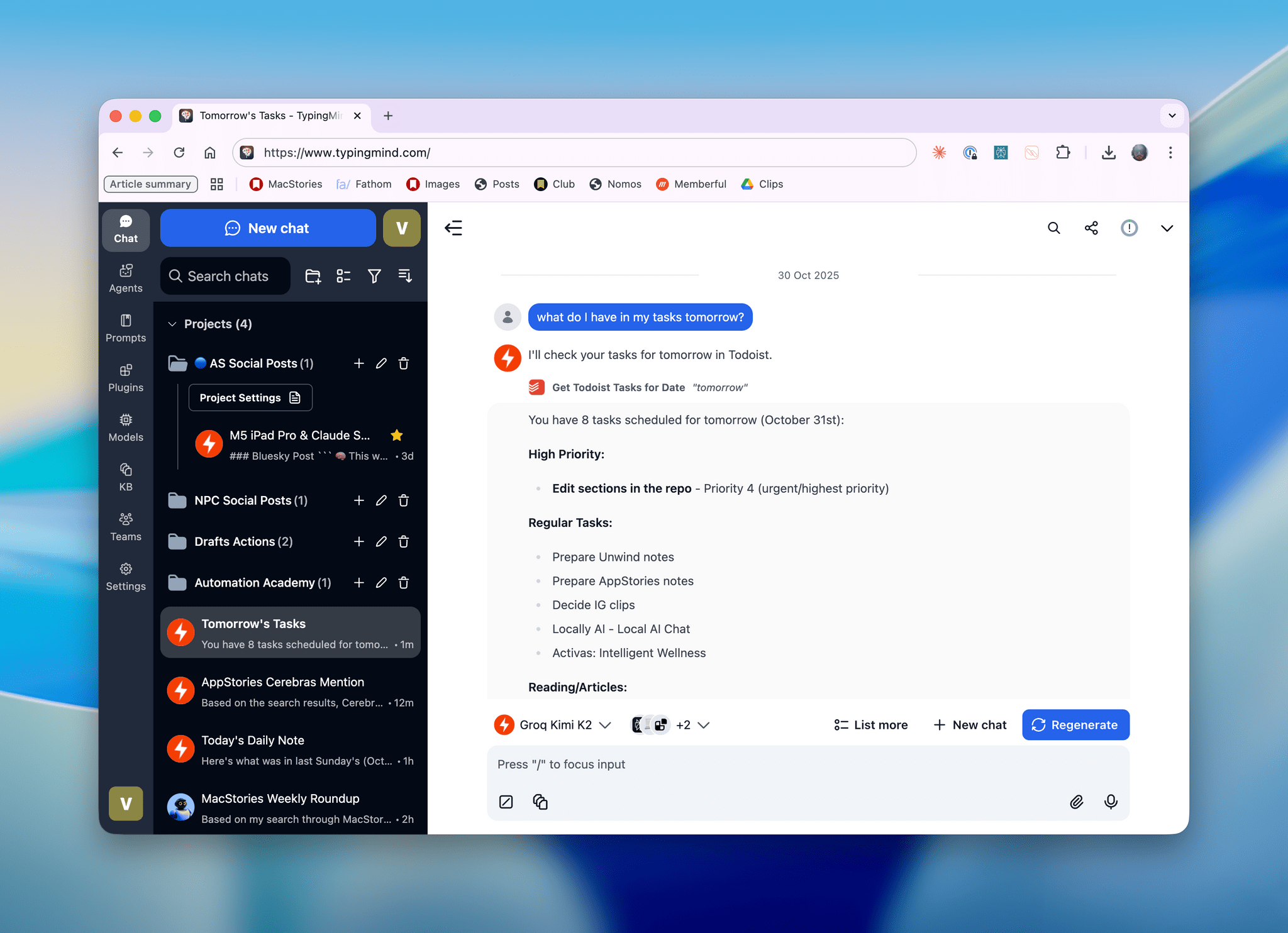
I’ll talk about this more in depth in Monday’s episode of AppStories (if you’re a Plus subscriber, it’ll be out on Sunday), but I wanted to post a quick note on the site to show off what I’ve been experimenting with this week. I started playing around with TypingMind, a web-based wrapper for all kinds of LLMs (from any provider you want to use), and, in the process, I’ve ended up recreating parts of my Claude setup with third-party apps…at a much, much higher speed. Here, let me show you with a video:
Kimi K2 hosted on Groq on the left.Replay
It all started because I heard great things about Kimi K2 (the latest open-source model by Chinese lab Moonshot AI) and its performance with agentic tool calls. The folks at Moonshot AI specifically post-trained Kimi K2 to be great at calling external tools, and I found that intriguing since most of my interactions with Claude – my LLM of choice these days – revolve around calling one of its connectors in conversations. At the same time, as I also shared on AppStories a while back, I’ve been fascinated by really fast inference as a feature of modern LLMs. If there’s something I dislike about Claude, it’s how slow it can often be at generating the first token as well as streaming a few tokens per second. A few weeks ago, I played around with Qwen3-Coder running on Cerebras and found its promise of 2,000 tokens per second to mostly hold true (it was more like 1,700 tps in practice) and game-changing. If you’re used to watching Claude’s responses slowly stream on-screen, fast inference can be eye-opening. Even if Qwen3-Coder was not as good as Claude Sonnet 4.5 at one-shotting vibe-coded Drafts actions, the back and forth that Cerebras’ fast inference allowed meant that I could immediately follow up in the conversation without waiting around.
But back to Kimi K2. I noticed that Groq (with a q, not the other thing) had been added to the service’s cloud-based infrastructure running at a healthy 200 tokens per second. That’s a far cry from Cerebras, but also more than three times the speed I get even from the faster Claude Haiku 4.5. Since Groq offers an OpenAI-compatible endpoint, which TypingMind supports, and Kimi K2 supports function calls based on the OpenAI spec, I figured I could have some fun with it.
I’ve been loving this setup. The video above is a comparison of Kimi K2 hosted on Groq – accessed from TypingMind – versus Haiku 4.5 running in Claude for iOS. In both cases, I’m asking the LLM to give me my list of tasks due today from Todoist. In Claude, that’s done via the Todoist MCP connector. In TypingMind, I vibe-coded (with Sonnet 4.5, in fact) a series of Todoist plugins that are making simple REST calls to the Todoist API as functions.
The difference is staggering. Kimi K2 with my TypingMind setup takes two seconds to call Todoist and generate a response; it takes 11 seconds for Haiku 4.5 to do the same. This proves a couple of things: pure tool calls based on functions that run code in a separate environment are naturally faster than the verbose, token-consuming nature of MCP; but regardless of that, fast inference means that Kimi K2 on Groq just flies through data coming from external services at blazing speed.
I’ve been so impressed by this, I’ve been building a whole suite of plugins to work with Notion and Todoist and had a wonderful time testing everything with Kimi K2 and TypingMind. (TypingMind has an excellent visual builder for function calls.) I can, in fact, confirm that Kimi K2 is great at calling multiple tools in a row (such as getting today’s date, finding tasks in a project, marking some of them as complete and rescheduling others) and I’ve been pleasantly surprised by how well it responds in English, too (if you want to learn more on how Moonshot AI did this, I recommend reading this).
I’m not in love with the fact that TypingMind doesn’t have a native iOS app, but it’s a really well built web app. I don’t think I’m going to abandon Claude any time soon (after all, Kimi K2 is a non-reasoning model, and I want to use one for long-running tasks), but this experiment has shown me that fast inference changed my perspective on what I want from a work-focused LLM. A faster infrastructure for Claude can’t come soon enough.