I received a top-of-the-line Mac Studio (M3 Ultra, 512 GB of RAM, 8 TB of storage) on loan from Apple last week, and I thought I’d use this opportunity to revive something I’ve been mulling over for some time: more short-form blogging on MacStories in the form of brief “notes” with a dedicated Notes category on the site. Expect more of these “low-pressure”, quick posts in the future.
I’ve been sent this Mac Studio as part of my ongoing experiments with assistive AI and automation, and one of the things I plan to do over the coming weeks and months is playing around with local LLMs that tap into the power of Apple Silicon and the incredible performance headroom afforded by the M3 Ultra and this computer’s specs. I have a lot to learn when it comes to local AI (my shortcuts and experiments so far have focused on cloud models and the Shortcuts app combined with the LLM CLI), but since I had to start somewhere, I downloaded LM Studio and Ollama, installed the llm-ollama plugin, and began experimenting with open-weights models (served from Hugging Face as well as the Ollama library) both in the GGUF format and Apple’s own MLX framework.
I posted some of these early tests on Bluesky. I ran the massive Qwen3-235B-A22B model (a Mixture-of-Experts model with 235 billion parameters, 22 billion of which activated at once) with both GGUF and MLX using the beta version of the LM Studio app, and these were the results:
- GGUF: 16 tokens/second, ~133 GB of RAM used
- MLX: 24 tok/sec, ~124 GB RAM
As you can see from these first benchmarks (both based on the 4-bit quant of Qwen3-235B-A22B), the Apple Silicon-optimized version of the model resulted in better performance both for token generation and memory usage. Regardless of the version, the Mac Studio absolutely didn’t care and I could barely hear the fans going.
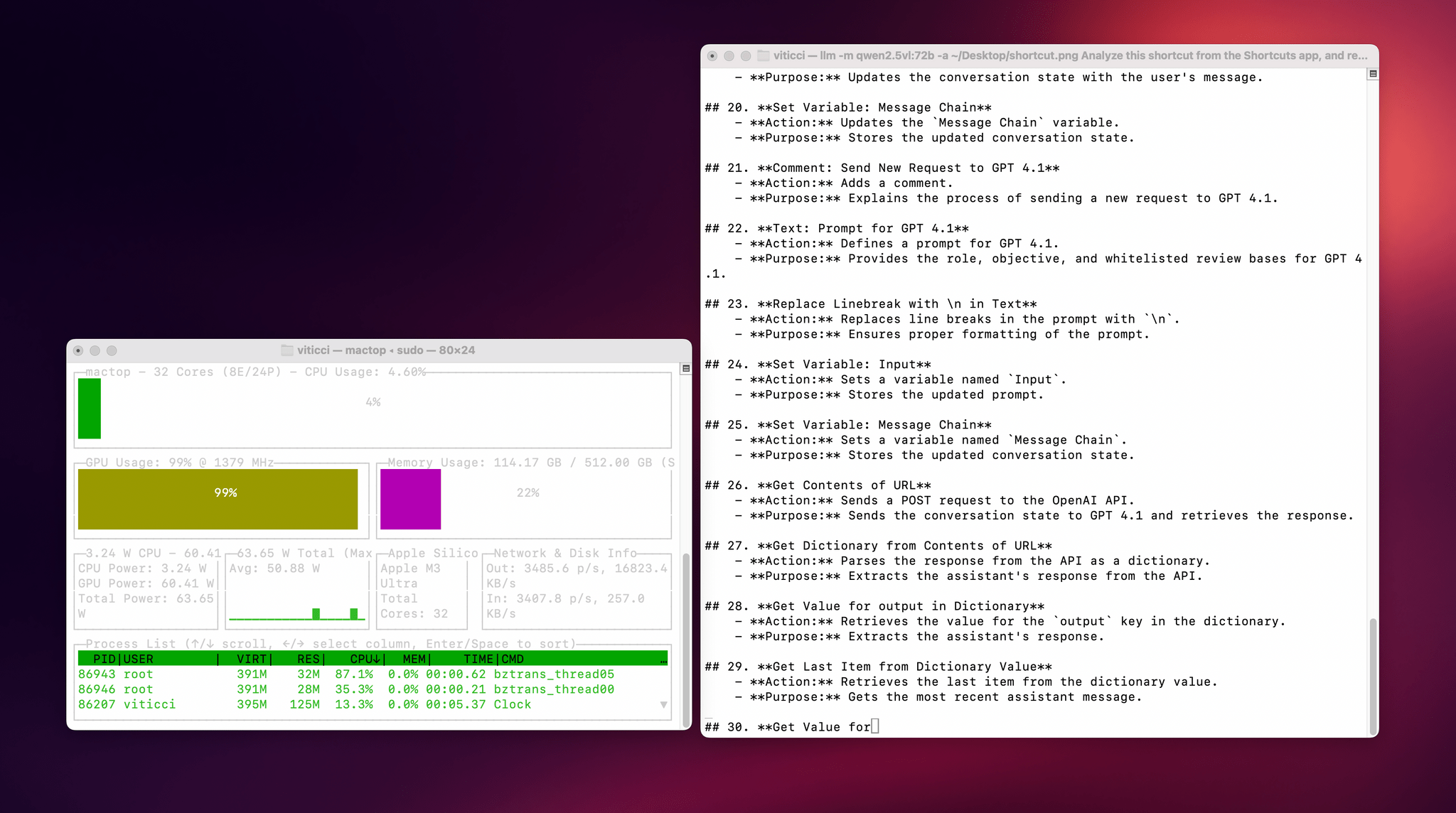
I also wanted to play around with the new generation of vision models (VLMs) to test modern OCR capabilities of these models. One of the tasks that has become kind of a personal AI eval for me lately is taking a long screenshot of a shortcut from the Shortcuts app (using CleanShot’s scrolling captures) and feed it either as a full-res PNG or PDF to an LLM. As I shared before, due to image compression, the vast majority of cloud LLMs either fail to accept the image as input or compresses the image so much that graphical artifacts lead to severe hallucinations in the text analysis of the image. Only o4-mini-high – thanks to its more agentic capabilities and tool-calling – was able to produce a decent output; even then, that was only possible because o4-mini-high decided to slice the image in multiple parts and iterate through each one with discrete pytesseract calls. The task took almost seven minutes to run in ChatGPT.
This morning, I installed the 72-billion parameter version of Qwen2.5-VL, gave it a full-resolution screenshot of a 40-action shortcut, and let it run with Ollama and llm-ollama. After 3.5 minutes and around 100 GB RAM usage, I got a really good, Markdown-formatted analysis of my shortcut back from the model.
To make the experience nicer, I even built a small local-scanning utility that lets me pick an image from Shortcuts and runs it through Qwen2.5-VL (72B) using the ‘Run Shell Script’ action on macOS. It worked beautifully on my first try. Amusingly, the smaller version of Qwen2.5-VL (32B) thought my photo of ergonomic mice was a “collection of seashells”. Fair enough: there’s a reason bigger models are heavier and costlier to run.
Given my struggles with OCR and document analysis with cloud-hosted models, I’m very excited about the potential of local VLMs that bypass memory constraints thanks to the M3 Ultra and provide accurate results in just a few minutes without having to upload private images or PDFs anywhere. I’ve been writing a lot about this idea of “hybrid automation” that combines traditional Mac scripting tools, Shortcuts, and LLMs to unlock workflows that just weren’t possible before; I feel like the power of this Mac Studio is going to be an amazing accelerator for that.
Next up on my list: understanding how to run MLX models with mlx-lm, investigating long-context models with dual-chunk attention support (looking at you, Qwen 2.5), and experimenting with Gemma 3. Fun times ahead!
](https://cdn.macstories.net/banneras-1629219199428.png)