OpenAI rolled out their updated Codex app for Mac yesterday and, among other things, they shipped a native computer use tool for macOS that lets Codex interact with multiple Mac apps in the background using parallel cursors that do not bring apps to the foreground when agents are interacting with them. The feature that OpenAI rolled out in Codex is literally based on the Sky app that I exclusively previewed last year, and which was later acquired by OpenAI along with the team that built it.
I feel like I’m in a pretty unique position to comment on all this since, as MacStories readers will recall, I was able to test Sky for several months last year before the team went radio-silent and joined OpenAI. Here’s the thing: I’m not exaggerating when I say that Codex now features the best computer use feature I have ever tested in any LLM or desktop agent. In fact, it’s even better than the computer use feature I used in Sky last year: Sky’s computer use was great, but it was considerably slower than Codex’s current one because it was running on Anthropic’s Claude models. With Codex for Mac today, even the (kind of slow) GPT 5.4 is faster than Sky ever was. But, using Codex with fast mode or – for simpler tasks – the Cerebras-hosted GPT-5.3-Codex-Spark model yields dramatically faster performance than Sky for Mac delivered in 2025.
But why is that? Allow me to explain. Most computer use models (such as the one in the Claude app, or even the just-released Personal Computer by Perplexity) rely on a combination of screen-recording capabilities and some AppleScript to either simulate virtual clicks on-screen and perform basic actions inside apps by calling osascript in a virtual shell. Sky was different, and Codex is different, and I can share more details today that I did not elaborate on when I wrote about Sky last year.
We all have Apple’s Accessibility team to thank for the technology that allows Codex’s computer use tool to exist. To build it, the Codex team took advantage of an advanced accessibility feature that allows third-party apps to read the “accessibility hierarchy” (also known as “AX Tree”) of any app open on macOS. My understanding is that this technology was primarily created to allow screen-readers and other assistive tools to work with Mac apps regardless of their automation/scripting features. In this case, it’s been repurposed as a way for Codex to ingest the full contents and hierarchy of any window and, essentially, load it as context for the LLM.
When I was told last year that this was how Sky worked behind the scenes, I instantly knew it reminded me of something, and I was right. We’ve seen the same technology being used before in UI Browser, the excellent (and sadly discontinued) app to inspect the visual hierarchy of any app that’s also powered by screen-reader APIs on macOS. All of this still applies to Codex’s computer use plugin today: pay attention to any chat where you’re using the plugin, and you’ll see 5.4 reason about the “accessibility tree” it wants to parse from any given application.
As someone who’s played around with GUI scripting and UI Browser many times over the years, let me tell you: this is not easy, and these frameworks were not meant for automation. For starters, they return a lot of text about any possible UI element, text field, or button inside a window. That text can be formatted in a variety of ways; it can be so deeply nested inside the XML-like structure returned by the AX framework, you often need to navigate 20 levels deep into a structure to find what you want. But this is what makes Codex’s computer use model different, why the Sky acquisition was a very clever move from OpenAI, and also why the reactions online seem overwhelmingly positive: Codex can “see” more inside apps and can control them more precisely than other models based solely on capturing screenshots, simulating clicks on certain coordinates, and running the occasional AppleScript. Codex can also do those things as fallback measures, but they’re not the primary drivers of its computer use plugin.
It also helps that computer use in Codex is exquisitely designed – not a surprise given OpenAI’s design team and the pedigree of the team behind this feature. The flow for granting permissions to the plugin is the best I’ve ever seen in a third-party Mac app – and it comes directly from Sky, which had the same onboarding experience. What Sky didn’t have is the new virtual cursor: the Codex team designed an entire system for it where the cursor can wiggle to show when the model is thinking, takes playful paths, and derives its color from the system’s wallpaper. I can only think of another company that sweats these kinds of UI details as much as the Codex team did here…and I’ll let you guess where several of Codex’s engineers and designers are, in fact, coming from.
I’ve been working with computer use in Codex all day, and while it is not as fast as a skilled human who knows a particular macOS interface well, it is very good at understanding and controlling any Mac app in the background a bit more slowly, with greater precision than competing features from Anthropic and Perplexity. That makes it ideal to automate busywork in Mac apps that do not offer an API or CLI, or which can’t be fully controlled with AppleScript. Let me give you some practical examples.
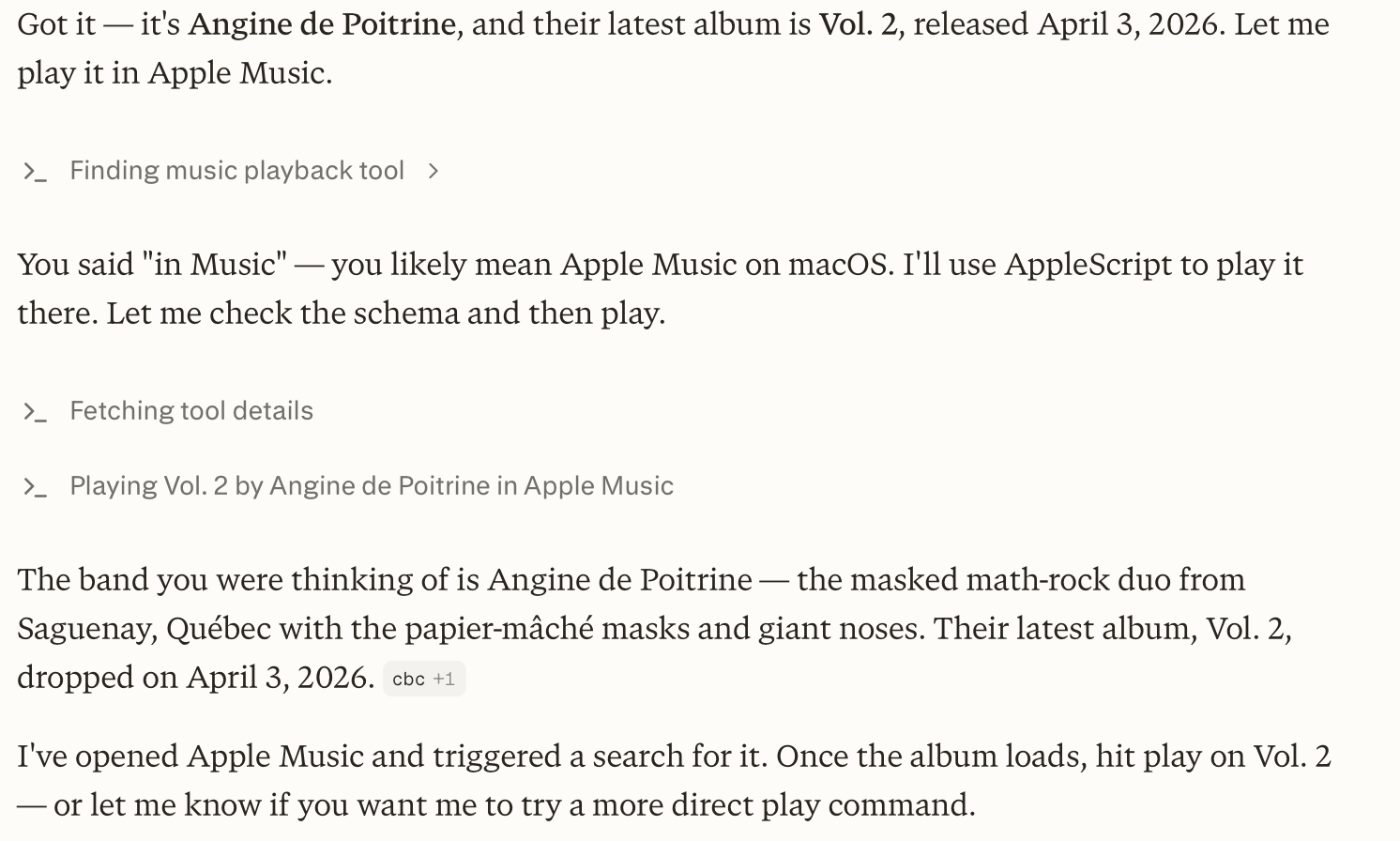
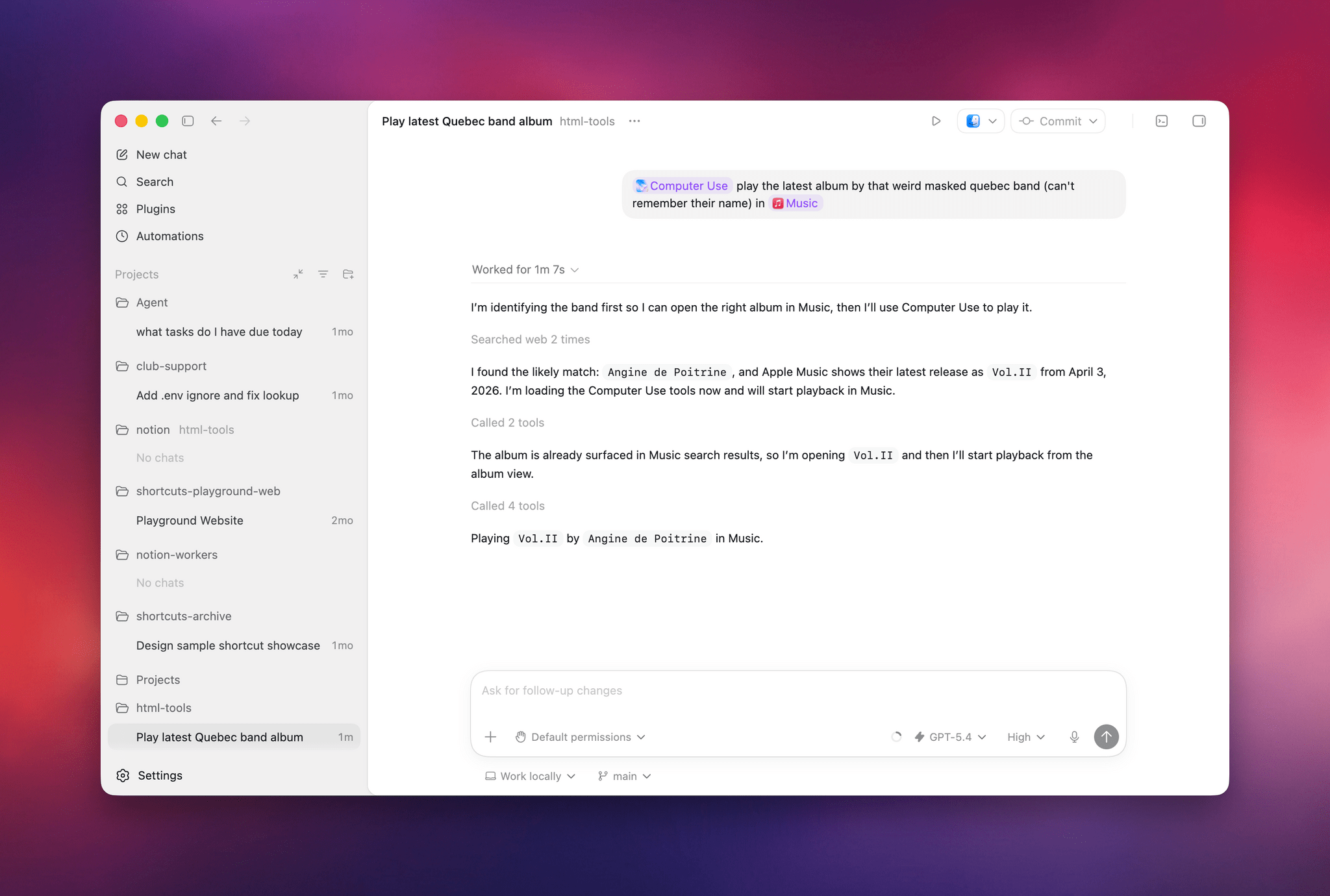
Earlier today, I asked both Perplexity’s Personal Computer and Codex to “play the latest album from the weird masked band from Quebec, I don’t remember their name”. I was referring to the exceptional Angine de Poitrine, of course. Both agents searched the web upfront and pinpointed my request, but when it came to actually controlling the Music app, Personal Computer stopped short of hitting the ‘Play’ button because its AppleScript integration couldn’t do it; Codex went ahead, opened the album with its virtual cursor, and started playing music.
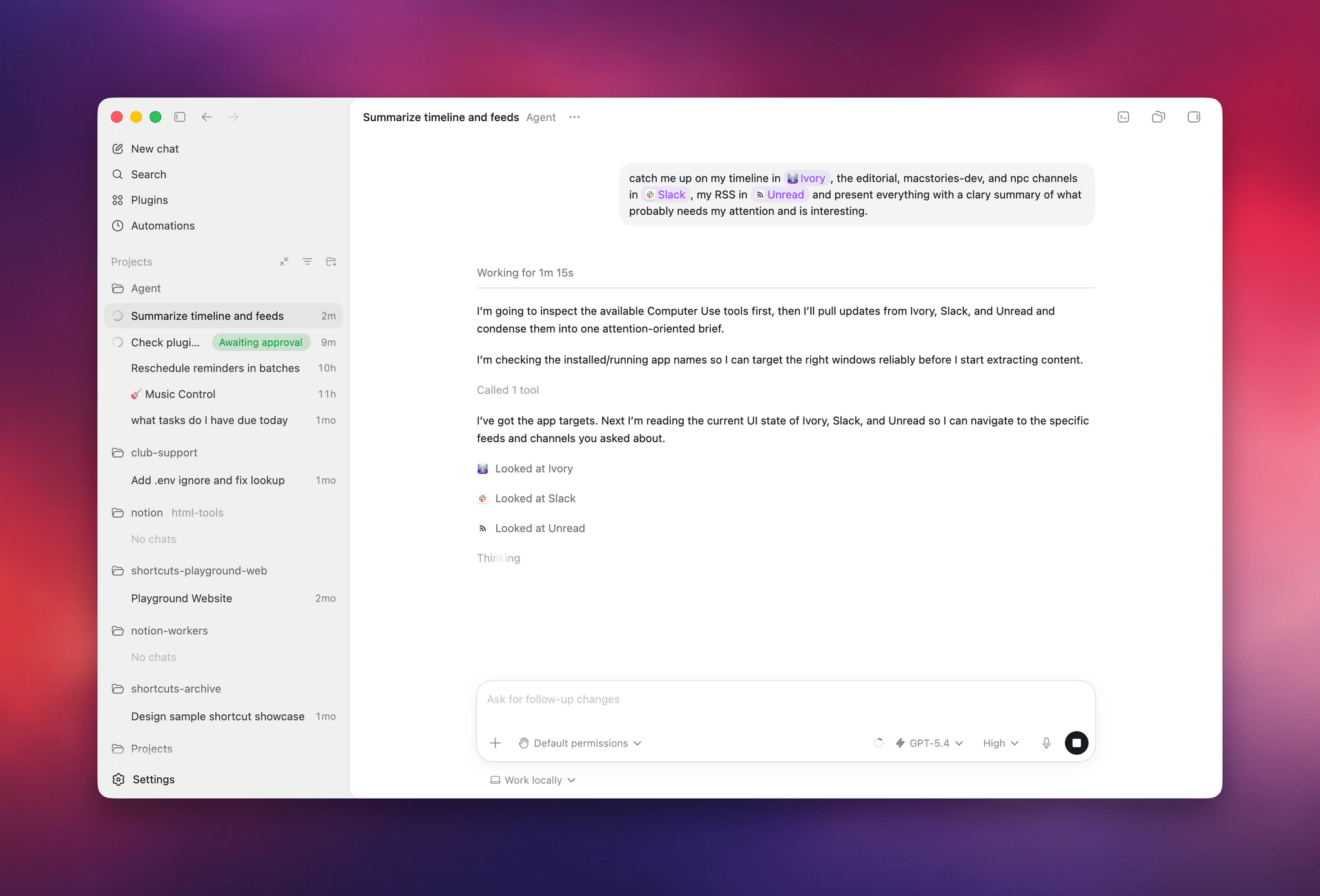
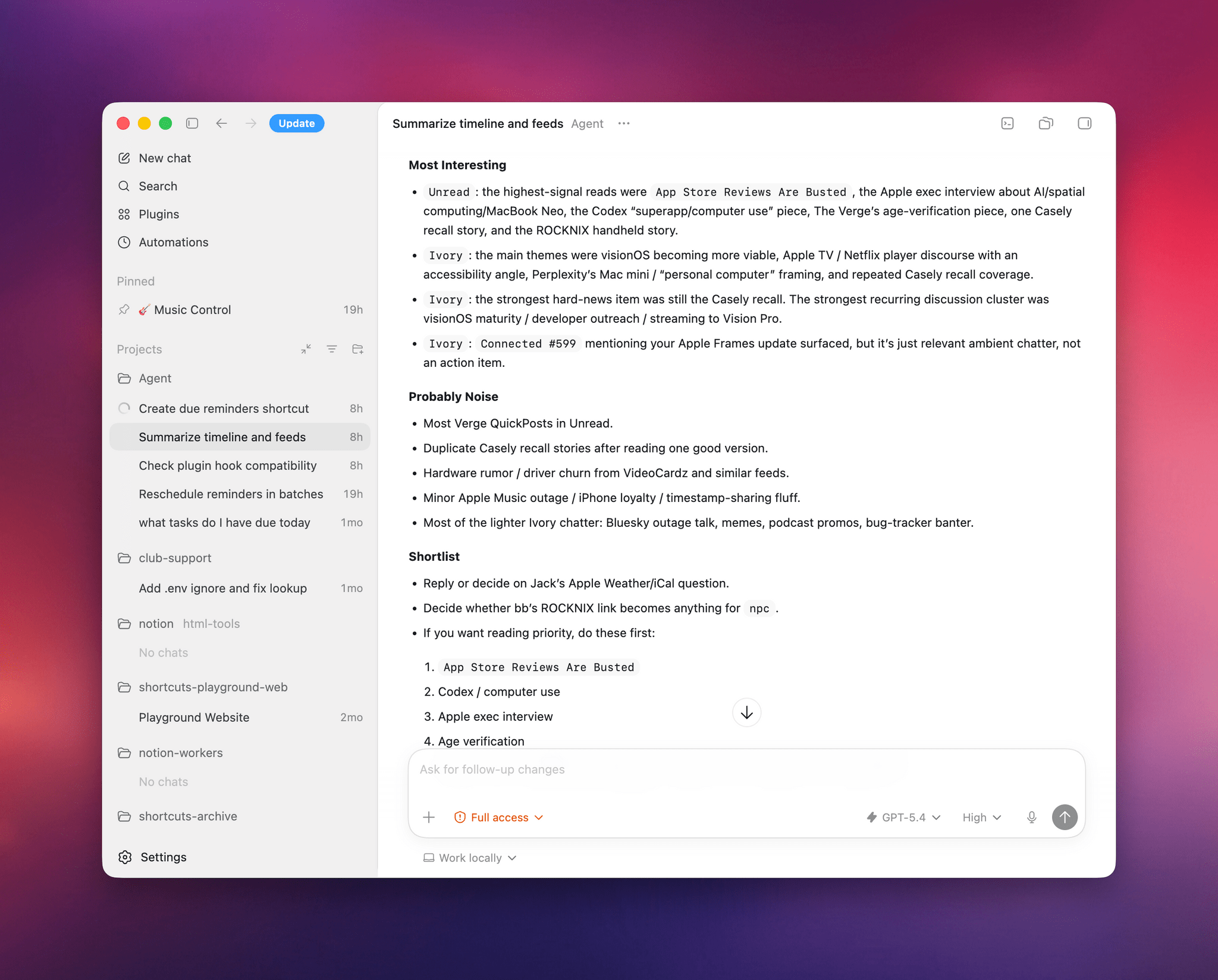
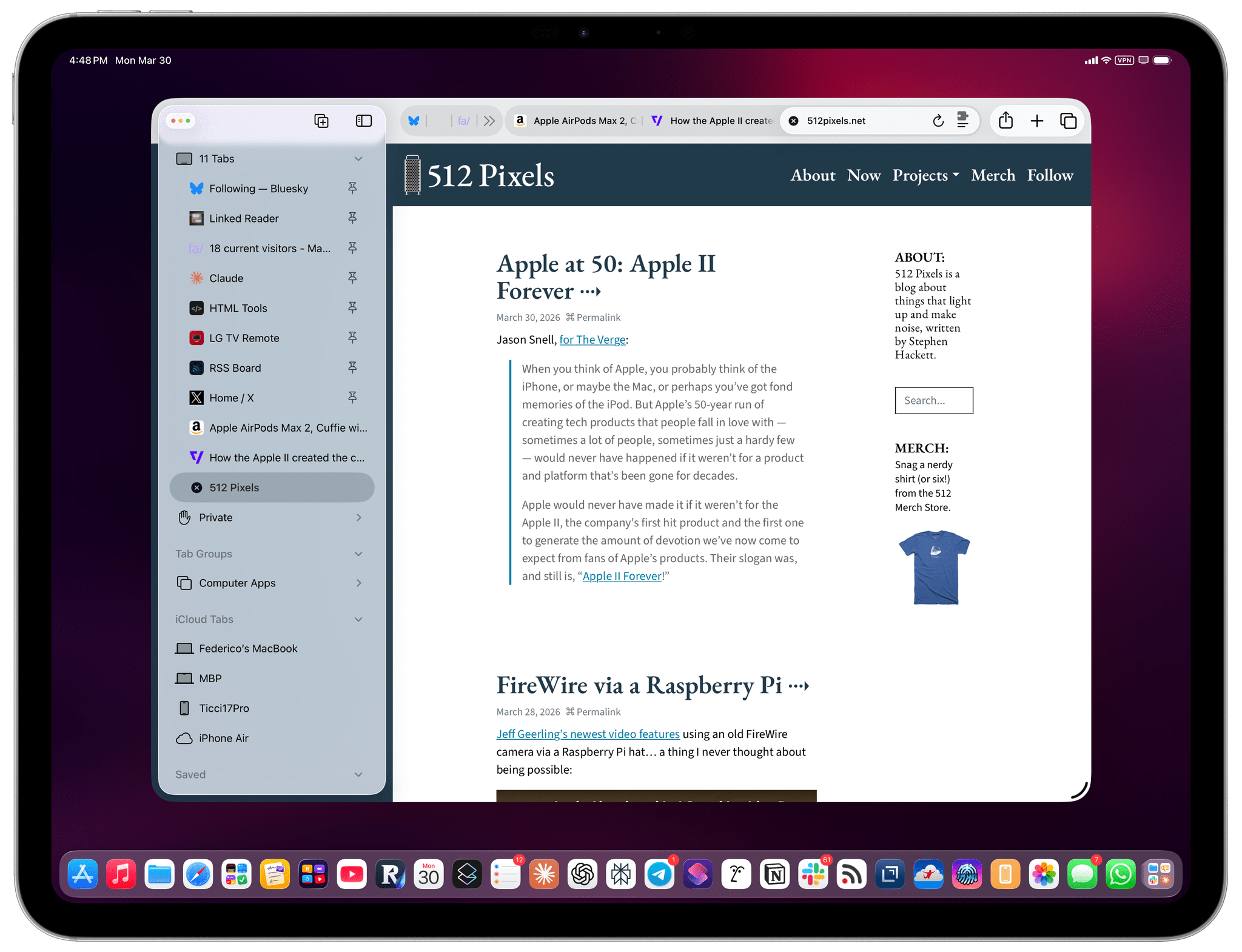
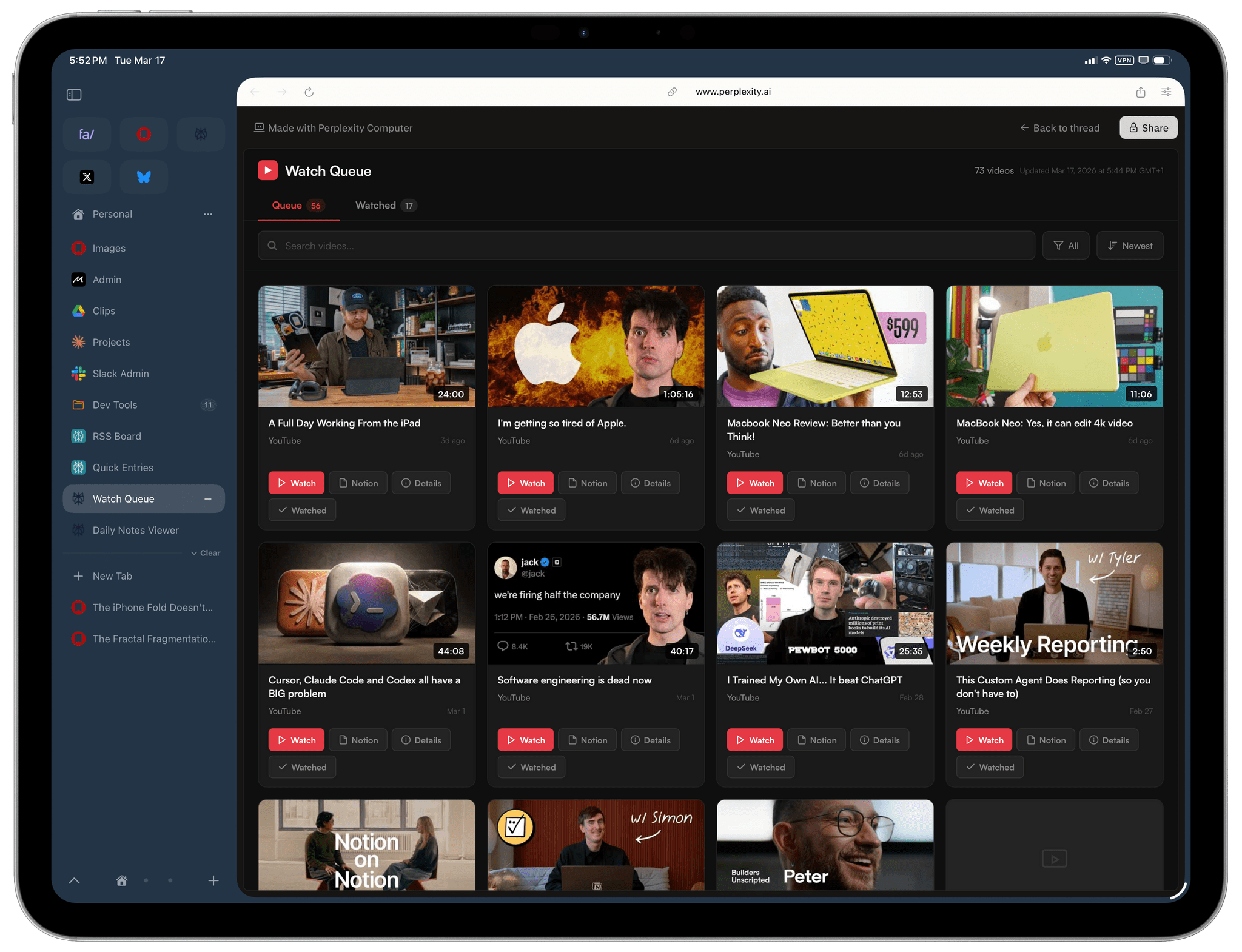
I also tested Codex by asking it to look at specific channels on Slack, my Ivory timeline, and the Unread app and give me a summary of interesting updates I should know about. Codex successfully deployed parallel cursors, started scrolling and clicking around all three apps, and produced a report that included updates gathered from those apps. Could I have scrolled the apps myself, one after the other, the old fashioned way? Sure. But as an “automation” that happened in the background while I was doing my email, it was pretty good.
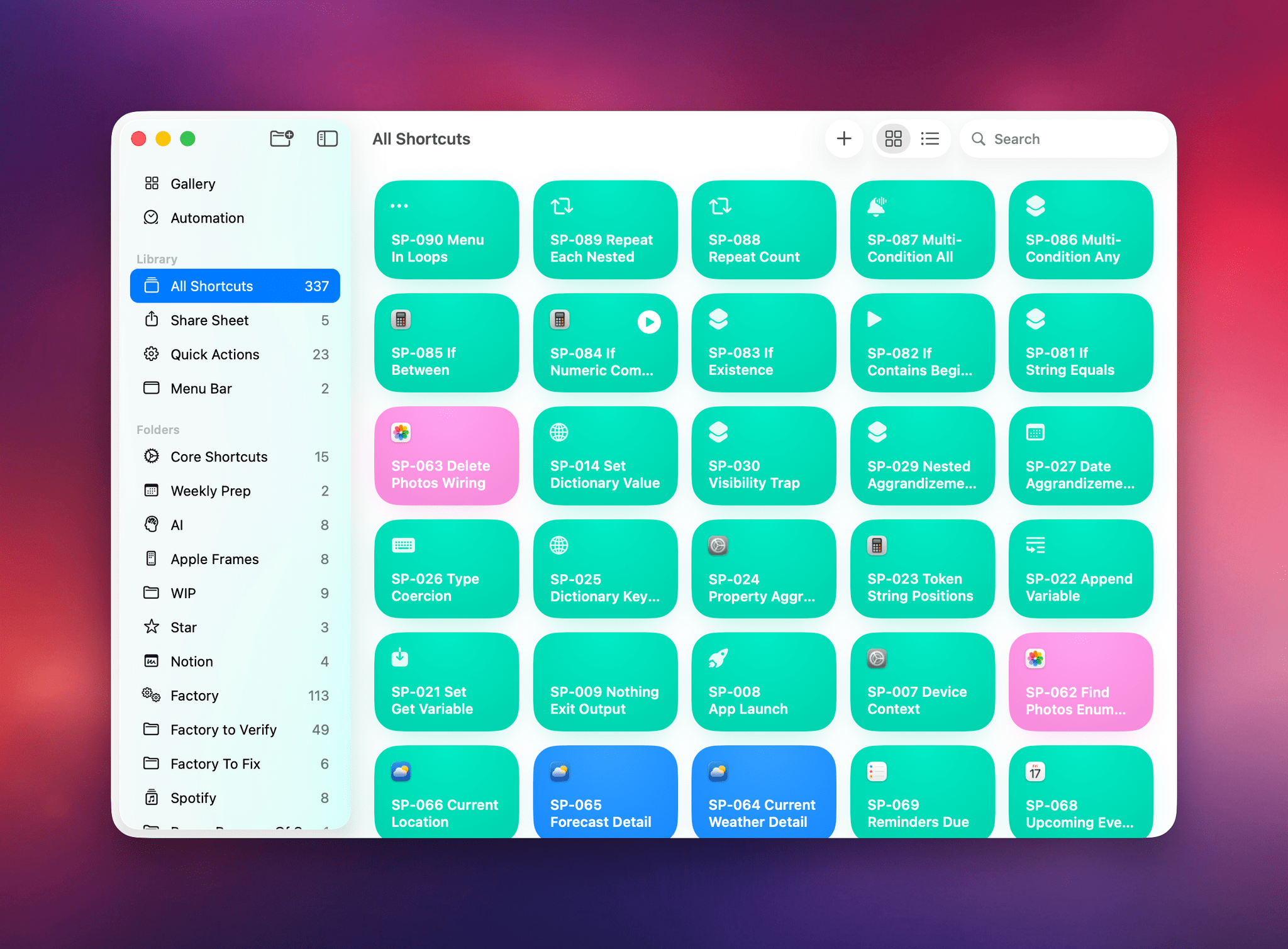
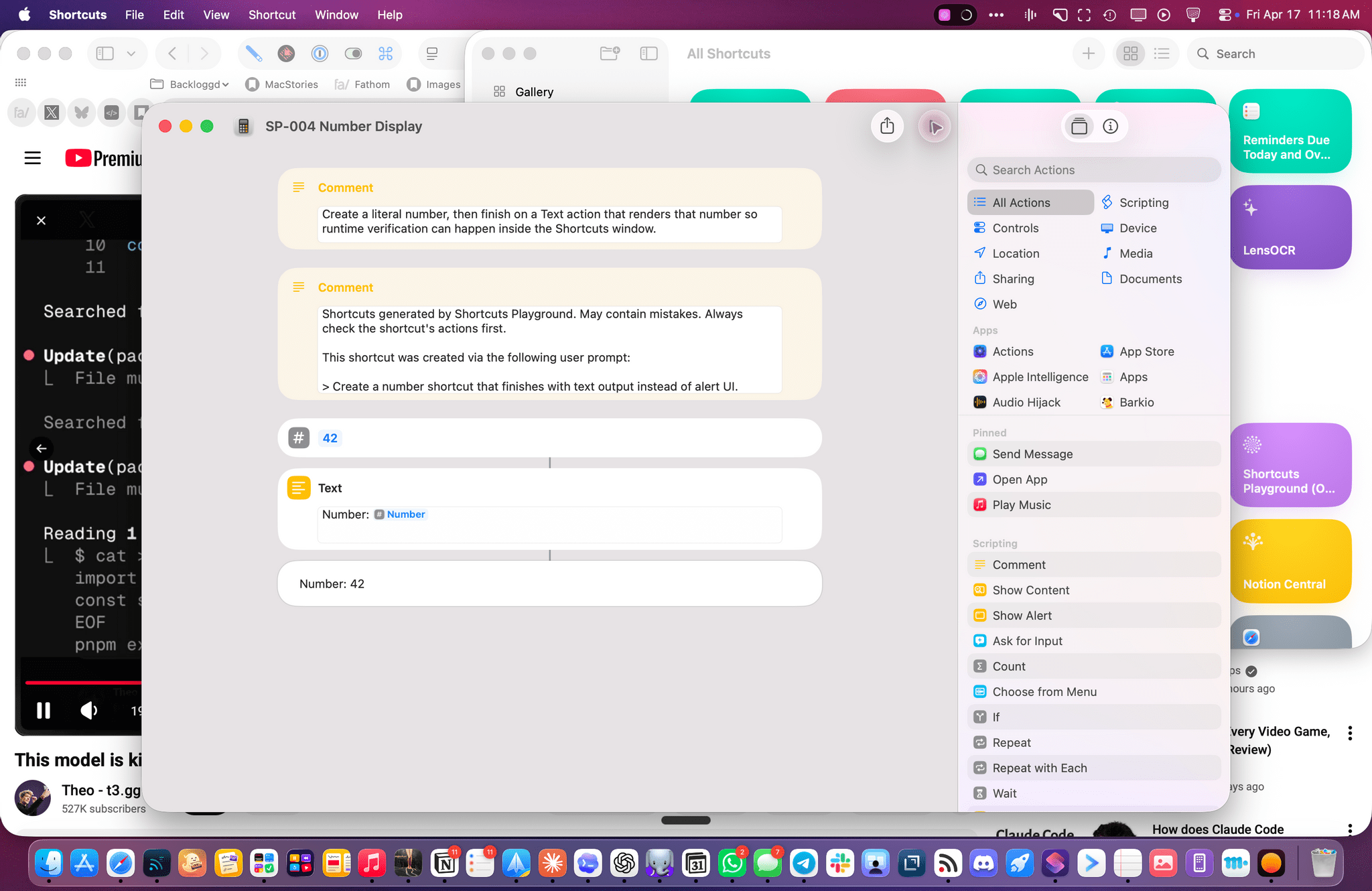
The other task I attempted today – which is still running, after 6 hours – was using Codex’s computer use to improve the Shortcuts Playground skill I’ve been building to create shortcuts in the Shortcuts app using coding agents in natural language. With Codex, I figured I could now ask the agent to run the skill, create shortcuts for me, but also click the resulting .shortcut files in Finder, install them, and test them for me in the Shortcuts app to spot any errors and further improve the skill. Not only was Codex’s computer use plugin able to successfully install dozens of shortcuts, but it also opened each, verified its output, and is currently evaluating what went wrong to improve some of the skill’s guidance and instructions.
So, long story short: Codex’s computer use plugin is the state of the art at the moment, and it’s the evolution of a strong foundation that I was able to test last year, which has been further refined and expanded by OpenAI. I’d like to see the company expand this plugin to the main ChatGPT for Mac experience (which is still stuck on the old Work with Apps integration), but, for now, I’ll take this feature inside Codex rather than the slower, and less capable, computer use models from other chatbots. More importantly, I’m happy to see that Sky ended up in good hands who can now deliver this product to the masses.