
Last week the MacStories team launched Project Calliope, an enormous new software project that we’ve been working on tirelessly for the last year. If you’ve been following along, you’ve heard us describe Calliope as a CMS; but from a software-engineering perspective, it’s actually a whole lot more. While we introduced Calliope as the foundation of our all-new Club MacStories and AppStories websites, we have much bigger plans for the new platform going forward. This is the foundation for the next generation of MacStories, from the website itself to many special projects in the future.
We’re extremely proud of what we’ve created here, and as the sole developer of Calliope, this post will be my deep dive into the more technical side of the project. Fair warning: this will be easier to follow if you’re a software developer (particularly a web or back-end developer), but I’ll be doing my best to give understandable explanations of the technologies involved. I also just want to talk about the journey we took to get here, the challenges we faced along the way, and the factors that drove us to this particular set of solutions.
Getting Started
Around WWDC 2020, Federico and John briefed me on some ideas they’d been thinking through for a new Club MacStories web app. They wanted to expand the Club with some new subscription tiers, make our email-only content available on the web, and enable full-text search of the back catalog. I’d already been working on a new internal MacStories image uploader web app (slowly, on the side from my main job at the time), and we decided that the new Club site would be a good next project. The timeline would be pretty long since this was side work, but the new project idea seemed fairly straightforward.
Then in late 2020, the pandemic spelled the end of the startup I’d been working at. I contacted Federico and John the same day, and in a fit of perfect timing, we were able to work something out. I came over full time to MacStories and started work on the newly code-named Project Calliope. While a new subscription-only podcast was added to the plate, we still figured we could get it launched some time in early 2021. I started picking technologies.
The Calliope Software Stack
Prior to this project, my background was primarily as a cloud engineer. I’d had some ideas for an ambitious, scaleable yet cost-effective back-end platform for years, and had already been dabbling in building it for our internal MacStories Images web app. It started with my insatiable interest in a back-end technology called Kubernetes; an interest that was conveniently enabled by a new Linode service offering.
Kubernetes

It’s a little much to go into Kubernetes here (okay it’s a lot much), but at a very high level, it’s a modern way to deploy back-end services onto a pool of servers. It’s best used with a “microservices” architecture (where you create many tiny services which each take care of a particular concern) rather than a more traditional “monolithic” architecture (where you write one giant service which pretty much does everything all at once). Calliope was built from the ground up to work in this paradigm, and our full platform consists of eight separate (micro)services and three separate database deployments, all managed seamlessly by Kubernetes.
Kubernetes has been around for a while, but it has generally been prohibitively expensive to run at a tiny company. This is especially the case when you want to run a “managed” Kubernetes deployment, which means a third-party company handles the Kubernetes controller so that you don’t have to (this can significantly decrease the complexity of using Kubernetes). Enter, Linode.
Linode launched Linode Kubernetes Engine, or LKE, in mid 2020. This is a managed Kubernetes deployment, and in an extremely Linode-like move, they don’t charge their customers for the server that runs the Kubernetes controllers. You only pay for what you directly run your services on.
I’m a huge Linode fan, and have been running my personal server projects with the company for many years, but here’s a disclaimer: Linode has been and continues to be a sponsor of AppStories. That said, we’re getting no special deals for using their technologies, and I personally made the decision to use LKE because I believe it to currently be the best managed Kubernetes offering for the price. We wouldn’t bet the future of MacStories on a service that we didn’t believe in.
With LKE, we’re able to afford a professional-grade managed Kubernetes installation. For many months of testing and one successful launch week, LKE has been rock solid for us.
Services
So Linode runs the servers and Kubernetes manages deployments, but what about the services themselves? We use three open-source services and five of our own, plus two different Redis installations (one Redis Cluster and one Redis Sentinel, for those interested) and one MariaDB database.
Open-Source Services

To manage incoming traffic and load-balancing between services, we run the incredible Ambassador Edge Stack. This Kubernetes-native, open-source software project manages mapping URL paths to particular back-end services, and load-balancing incoming traffic across multiple service instances (among other things). For example, on launch day, we were running five different instances of our API service. Ambassador spread incoming traffic out across all five instances of this service, even though all of those requests were for the same URL. Ambassador has an enormous amount of excellent features, and if you’re looking for a load balancer, I highly recommend checking it out.
Collecting metrics is a key part of successfully managing any software platform, but perhaps especially for one built with a microservices architecture since problems can occur from so many different sources. We use the open-source project Prometheus to collect metrics from throughout our system, and the open-source project Grafana to graph these metrics in an understandable way. Using these services, we can monitor CPU and memory usage (as well as many more metrics) for all of our services at a glance. When a problem occurs, a spike on a line graph will generally point us immediately in the right direction.
Internal Services

Internally, we’ve built our platform on five services: an authentication service, a proxy service, an API service, a web server, and a Discord bot. On launch day, we deployed 18 separate service instances from these five sources to give ourselves full confidence that the platform would withstand any unexpected traffic bottlenecks. A week later, we’ve scaled down to just 8 total service instances across far fewer servers since things have been very stable, and no particular concerns were identified.
We built our back-end services on Node.js, and our front-end website and web server on React via Next.js. Since everyone immediately follows that by asking me if I use JavaScript or TypeScript, I suppose I’ll head that off: all of our services are written in vanilla JavaScript. I have thoughts, but I’m saving them exclusively for our Club MacStories Discord JavaScript Throw-down later this week. If you want to argue about TypeScript with me and a bunch of other nerds, I guess you’ll have to join Club MacStories+ or Club Premier1.
Building a CMS
To quote the words of every developer who’s built a CMS in the last decade: we didn’t set out to build a CMS. Our project seemed more manageable at the start (don’t they all?), so we kicked things off by building on top of the popular open-source CMS Ghost.
I picked Ghost after a lot of research, and I still think it’s a solid product for some businesses, but ultimately it fell down for us on a few important levels. First, it messed with our markup. Whatever they may say in their product marketing, Ghost doesn’t really want you to write in Markdown. While they claim that their editor supports Markdown, it’s really a full on WYSIWYG editor that automatically converts Markdown to rich text as you type (even if you use one of their “Markdown blocks”).
This was fine at first. I had expected that I would need to replace Ghost’s writing front-end at some point anyway. I still planned to use it as a “headless” CMS, where we would use its API and database to store our content records, but edit and publish that content from our own custom interface. Unfortunately, Ghost still messed with our markup. Even when using the API, and trying to manually wrap content in HTML or Markdown blocks, the text that came out of Ghost was subtly different than the text that went in.
I even tried wrapping everything as an HTML code block using <pre> and <code> tags. That solved almost every issue, but Ghost still replaced relative URLs with its own absolute URL, and it still stripped HTML comments out. Why? I honestly do not know.
Okay, so Ghost messes with markup. Fine, I should probably pick a different CMS. Except I didn’t arrive at full-blown exasperation with Ghost until late into the process, and also I’d already been hacking my way around other problems which other CMSes wouldn’t have solved either.
Parent-Child Posts
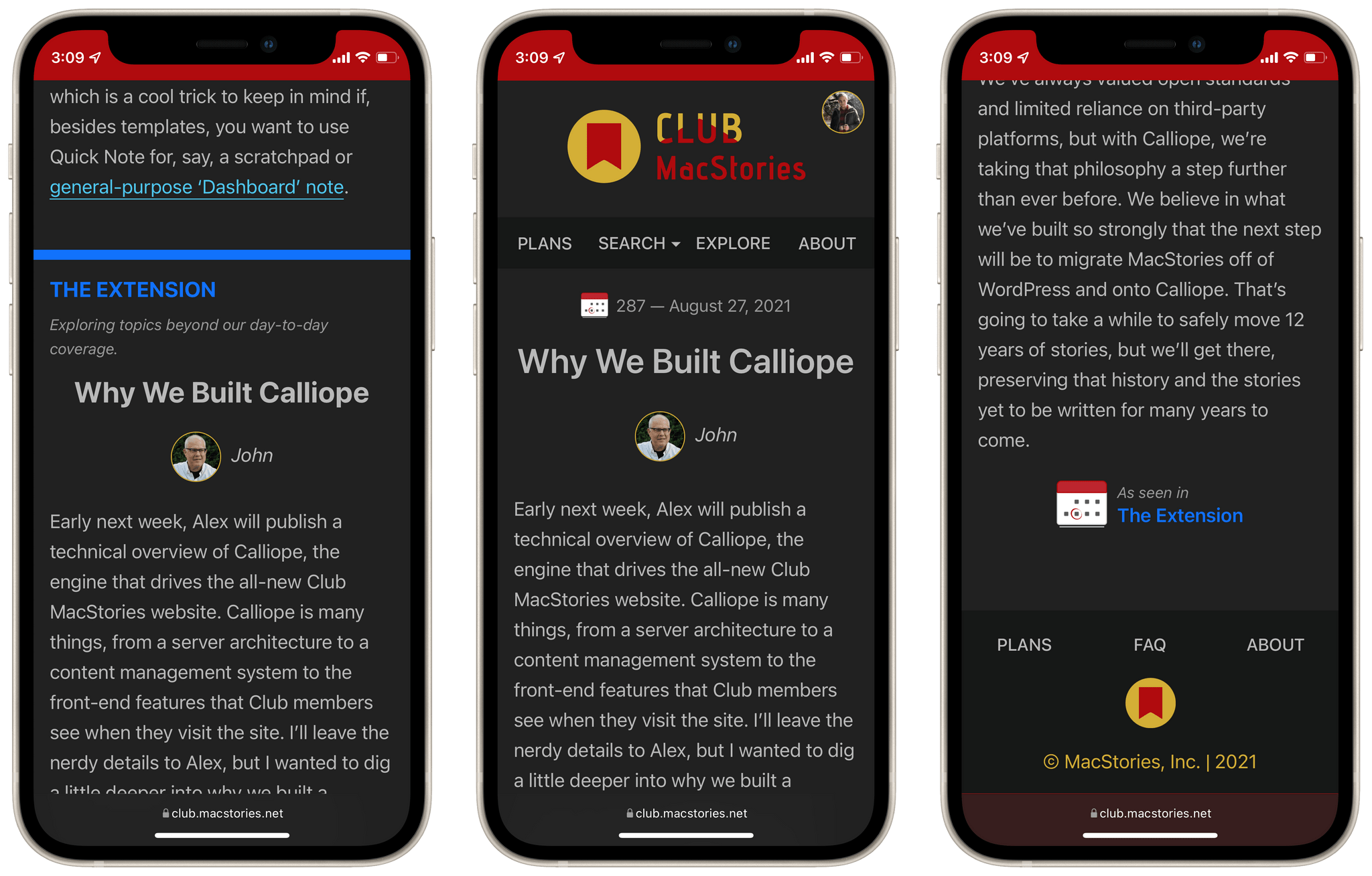
One of Calliope’s big features is the ability to create posts with a parent-child relationship. For example, our weekly newsletter for Club MacStories members is made up of a variety of different sections. Each of these sections are written independently, and generally by different authors. It made sense that users should be able to see each section by itself — as a standalone post on the new Club MacStories website. But, our newsletters were still ultimately a single whole. So sections needed to exist on their own, but also exist within the greater newsletter.
This is how we arrived at parent-child posts. Each week, MacStories writers create their own posts for the MacStories Weekly newsletter. They tag those posts according to the upcoming MacStories Weekly issue number. Calliope then takes all of these posts and combines them into one single MacStories Weekly issue.
On the homepage of the new Club MacStories website, you’ll see only the full “parent” MacStories Weekly issues. Click into one and you can scroll through all of the included sections, each with a fancy colored section header. Click on any section header though, and you’ll be taken to that section’s individual post. You can share a link directly to that standalone section, and it includes a back-link to the MacStories Weekly issue that it belongs to. With this relationship, users can bob in and out of the individual sections and the Weekly issue they belong to.
As far as I’m aware, no other CMS supports a feature like this. Months into Calliope’s development process, I had hacked this functionality onto Ghost. It worked, but it was slowing things down much more than it should have, and it really was starting to feel like a pile of hacks. While another CMS might have solved my frustration with Ghost changing my markup, this issue with updating so many posts at once was going to persist.
Dropping Ghost

As we continued building Calliope and found more and more needs for the project, it became clear that we had use cases for automatically applying filters to our Markdown text as it went into the system, as well as filters to our HTML text that was generated from the Markdown. We even needed to apply filters to the HTML as it was coming out of the CMS, in order to insert various dynamic elements based on the subscription tier of the requesting user. Things were getting complicated, and we were implementing custom functionality on essentially every side of Ghost. We eventually arrived at the point where Ghost was acting as a database and an API, but essentially nothing else.
Right around then is when I noticed Ghost replacing all of our relative URLs with its own absolute URLs. For example, if we tried to link to the Club MacStories plans page via /plans, Ghost would change that link to https://ghost/plans. Obviously, that isn’t even a functional URL. We were running Ghost within a private network managed by Kubernetes, where it lived at the URL https://ghost. From outside the private network, that link of course does nothing. Ghost supported no option to disable this link-replacement functionality, and we couldn’t just give it the real external link without breaking it in other ways.
This is the point at which I made a decision. Without quite informing Federico and John of my plans, I spent one of the most exhausting weekends of my life writing an entire CMS database and API layer. Between our call on Thursday and our call on Tuesday, I completed and successfully deployed a fully-functioning implementation of these features, including hooking them into our existing infrastructure. Just like that, Ghost was gone, and we had built a CMS.
Maybe I could have swapped Ghost out for a different headless CMS instead, but at this point we were months into the development process, and I was fed up with unexpected nasty surprises. Building on an existing CMS was useful for us to hone in on our desired feature set. Once that was nailed down though, I felt better filling in the API and managing the database rather than jumping into another unknown third-party CMS’s fun house. This also allowed me to tune our database objects to hold exactly the data we needed from them, including both the raw Markdown and filtered HTML text for each of our posts.
As an added bonus, my new database layer ran nearly 10 times faster than Ghost when updating a series of posts in a row — an operation we commonly needed to execute due to our unique parent-child post relationships for MacStories Weekly and Monthly Log issues. With a purpose-built API for accomplishing this kind of task, it no longer felt like we were piling up hacks to get the functionality we wanted from our platform.
The Front End

At MacStories, we’re big fans of open web standards. While there were a lot of fancy features that we wanted to pack into Calliope, we ultimately wanted to deliver a static website with some HTML, CSS, and JavaScript. This presented a number of challenges that we needed to solve.
React is an extremely cool project for modern web development, but I’ve never liked the idea of “single-page web apps.” Many React web apps these days are really just a single JavaScript-generated page which fakes browser navigation and dynamically pulls content from the server after arriving on the client’s browser. While this makes a lot of sense in certain contexts, I don’t think it’s the best approach for blog-style websites.
Instead, I’ve always preferred a more classic architecture: a website where each URL you visit loads a particular page from the server, and that page’s contents were statically generated ahead of time so that they can be rapidly retrieved. Users never have to wait on client-side loading spinners, and your whole site runs faster because the first paint includes the actual text that the user wants.
That said, I also recognize that React is a pretty excellent framework to develop in. It can seriously improve developer efficiency and code architecture for a complicated website, and it’s simply a nice and well-supported modern framework. I wanted to have my cake and eat it too: develop in React but deploy as a static website. Thankfully, this is exactly what the Next.js framework is designed to do.
Next.js is a framework built on top of React which provides (among many other things) advanced tooling for generating static content at build time. You can write your website’s code using React, but it gets rendered out into static HTML, CSS, JS, and JSON files to be served to users. Technically it still hydrates the page with JavaScript, but with careful design you can cut down on the amount that you’re depending on JS.
On the new Club MacStories website, for instance, you can disable JavaScript entirely and reload the page and you’ll still be able to read the text content. Signing in won’t work, nor will many of the site’s features like Search or Explore, but if you’re already signed in then basic navigation and reading posts remains possible. This isn’t an argument that our site doesn’t depend on JavaScript — it definitely does and I don’t think that’s a bad thing — but simply a nice illustration of how we’ve built a text-first experience.
Making a Static Website “Dynamic”
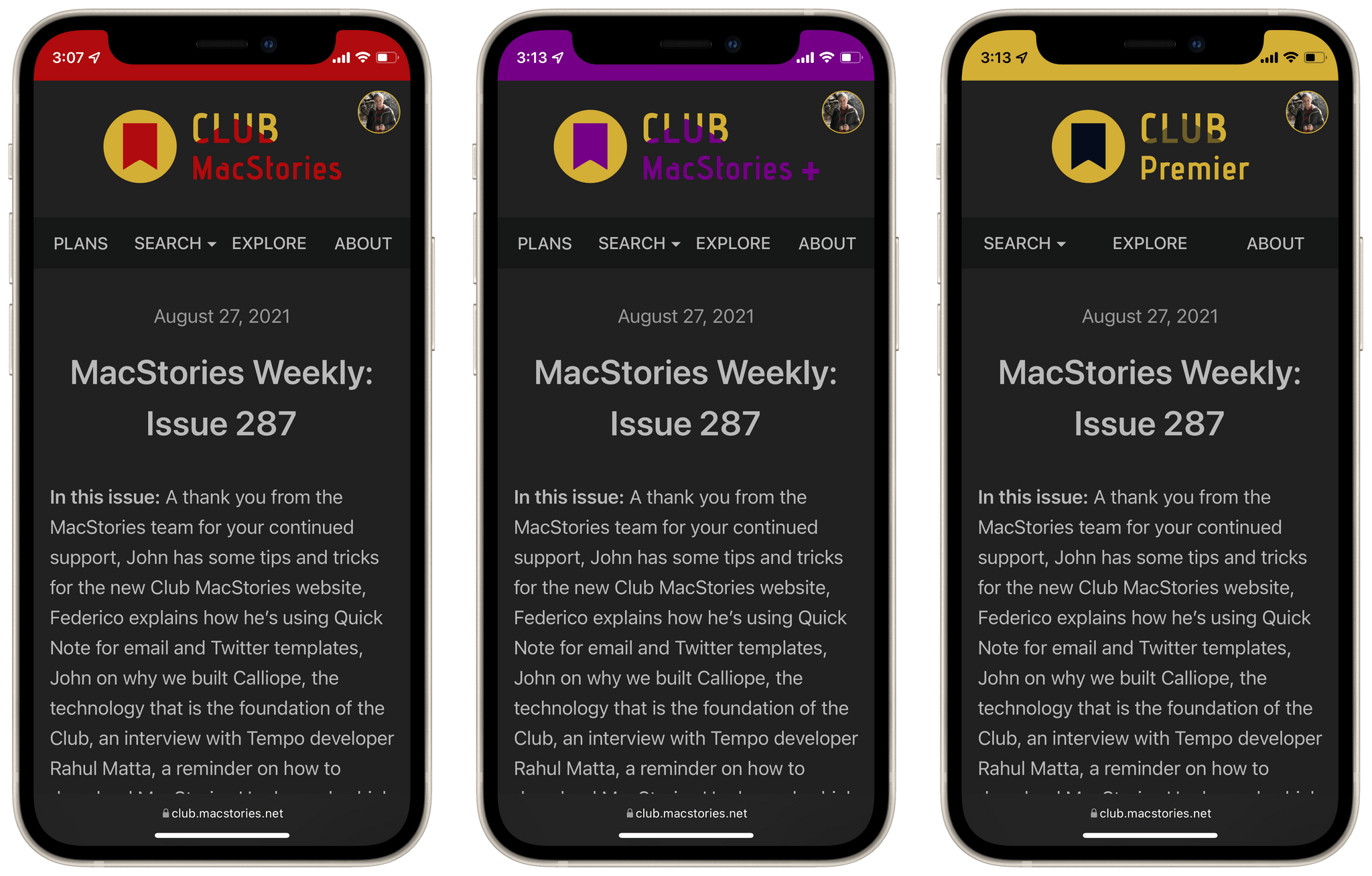
Building a static website was a lovely ideal, but we also needed a paywall and multiple different subscription tier levels. Public users should see truncated posts and a request to sign in or sign up. Club MacStories subscribers can see MacStories Weekly posts, but can’t see AppStories+ posts. AppStories+ subscribers can see the latter, but get truncated versions of the former. Club MacStories+ includes even more non-truncated content, and the great all-seeing eye of Club Premier reveals everything. You can see how things get complicated quickly.
The most common solution here would probably be to just drop our silly static pipe dream and create a dynamic website. Then each time a user requested a page, it would get generated dynamically on our server with the content available to that user’s subscription level. Easy enough to implement, but this causes more server load and slows down the speed of content delivery to our users. I didn’t like it.
Instead, I deployed our Next.js instance onto a private network in our Kubernetes back end. This means that there’s no way to access the service from the public Internet, and thus it can exist in a happy land of no authentication. From this happy place, Next.js generates distinct static versions of the website at build time — one for each subscription tier level and another for public users.
So now the static content existed in our protected Next.js web server, but we still needed authenticated access to it. For this, I built an authentication proxy service which lives at the public URLs for each of our new websites. This is the public gateway into our system, and all requests going in and out of it are authenticated via our auth service and Memberful. Once a request is authenticated, the proxy uses Kubernetes networking to communicate with the private Next.js web server and sends back the static version of the webpage which that particular user has access to.
For users, this is seamless. When you’re signed out, you see the public version of the static website. Sign in and you automatically get sent the authenticated version for your particular subscription tier. While these are technically different versions of the website, they live at the exact same public URLs, thus making the pages appear to change dynamically even though we’re really always returning static content.
Getting Wild with Faux Dynamism
I’m pretty proud of this faux-dynamic architecture, so I decided to make even more use of it by opening it up directly to content authors in the Calliope CMS. Using some very simple syntax directly in their Markdown text, authors are able to target blocks of content at particular tiers of subscribers. This means that within the same post, a Premier member might get some extra content that simply does not appear when viewed by a standard Club member. Alternatively, a public user might see a block of text encouraging them to sign up for the Club, but a subscribed member would not see this text all. These capabilities are entirely controllable by our authors — directly within their text using minimal extra markup — meaning Federico, John and I are able to easily tailor the content we’re writing to best fit each tier of our subscribers.
As examples, we use this feature liberally in the About pages for Club MacStories and AppStories. These pages are each generated by single text documents, but each document includes a variety of conditional blocks to make the output maximally relevant to whatever user is reading it. We also use this in AppStories posts on the AppStories website: if you’re an AppStories+ or Club Premier subscriber then you get to see the extra show notes from the subscriber-only section of the podcast. If you’re not subscribed to one of these tier levels then that content is omitted. The audio player also of course adjusts to play the version of the show that you have access to.
I’ve always found it distasteful when CMSes require dynamic content “blocks” to be created from within their built-in editors. In other words, authors need to paste their writing into the web editor and then drag-and-drop extra content blocks after the fact. Calliope is designed to make every extra feature available purely via special Markdown syntax, including dynamic element insertions (such as the AppStories audio player) and subscription-targeting conditional formatting. This enables authors to use the writing app of their choice for their entire posts, then just paste into Calliope’s web editor at the end when they’re ready to preview and publish. Once content is published, it gets rendered out statically for each version of the website before being served to users.
Importing the Back Catalog

With Calliope’s architecture ready to go, it was time to undertake the mammoth task of importing over 350 back-issues of MacStories Weekly and Monthly Log. This content did not exist in a different CMS which I could have written an easy import script to pull from (thankfully I was able to script the import of the 237 AppStories posts from our previous WordPress installation). Instead, our newsletter content existed only as archived Mailchimp emails.
If you’ve ever had the misfortune of needing to inspect the HTML content of Mailchimp emails, you’ll know that it’s a terrifying mess. Your text is buried under layers upon layers of <table>, <tbody>, <tr> and <td> elements. Amongst these are clusters of ID-less and class-less <div>s and <span>s. It is not a pretty sight. Still, with the only alternative being a fully-manual content import that would have taken months, I endeavored to build a parser.
Thanks to a combination of Cheerio-powered HTML spelunking, the HTML-to-Markdown conversion package Turndown, and an enormous amount of regex, my efforts came to fruition.
For each issue of MacStories Weekly or our Monthly Log, we would forward the URL of the Mailchimp-generated web archive to my back-end parser service (this was all done using a custom front-end interface for parsing these issues). The parser would pull the archive’s HTML contents and pass it to Cheerio, which would transform it into a traversable virtual DOM tree.
Here’s where I found some magic elements in Mailchimp’s markup which allowed me to parse the issue’s full contents. Using Cheerio, I grabbed the first table with the class name .mcnCodeBlock. I then took this table’s parent element (a class-less <td>) and output its contents as raw HTML. This HTML was passed to Turndown, which transformed it into Markdown.
Transforming to Markdown flattened out the content to remove the layers of nested table elements, but during this flattening I had to execute a series of custom Turndown rules to save some formatting which would otherwise be erased. For instance, to attach image captions to their images, I needed to identify each instance of an <img> element with the class .mcnImage, then traverse the DOM tree up three parent levels, across one sibling level, and down one child level. If this DOM path exists, then this is where the image’s caption would be. If it doesn’t exist then the image was caption-less.
My 5-months-later self actively cannot comprehend how the most ridiculous of these Turndown rules actually works. But according to my code comments, this is how the parser identifies post authors for each section:
- Each time an element with the
.mcnTextBlockInnerclass is found, traverse 6 levels of children down the DOM tree. If you find an<img>element here (???), then continue. - From the
.mcnTextBlockInnerelement, traverse one child down, one sibling across, four children down, then another sibling across. Pull the text contents of the element that exists there. - Does that text content start with letters followed by a colon? If so, this is a post author.
The convolution hurts me. Yet this code nailed almost every single author for every section of more than 350 Mailchimp email issues.
After Turndown processed the HTML into Markdown, that Markdown content was funneled through a series of complicated regular expressions. These identified each section, including the section type, title, subtitle, authors, and external links. This content was then retuned to the front-end parsing interface.
Back on the front end, we’d see a series of posts appear along with buttons to add the content into our CMS. I didn’t automate this part because, despite my best parser efforts, there were still plenty of errors in the final output of certain sections (especially in some of our very early issues). We needed to do manual spot-checks of each section as we imported them in order to verify the validity of our content.
Once the parser was finished, it took John, Federico, and myself a little less than two weeks to complete the full import of our Mailchimp back catalog into our new Calliope CMS. That means all of the parser’s code is now useless going forward, but it was a pretty invaluable tool for our big import job, and I’m very pleased with how much it was able to automate under such difficult conditions.
The Next Generation of MacStories

After nearly a year of tireless work from the entire MacStories team, it feels amazing to have finally shipped Calliope. We are extremely proud of what we built here, and felt especially so after the new software stack held up perfectly on launch day. It’s been a long year, and we’re all looking forward to getting some rest before we begin the next phase.
While Club MacStories and AppStories were great as fairly low-traffic candidates to launch with, our next big test for this new platform is to migrate MacStories itself to it. We have lots of special plans for that move and beyond, and we can’t wait to show them off before too long.
In the meantime, I hope this post gave some interesting insight into our new software stack. If you’re curious about anything I missed, feel free to ask me on Twitter, or better yet, on the Club MacStories+ Discord. We built Calliope on open standards and leveraged quite a few open-source projects, so even though our project itself is not currently open-source, we still love discussing how it works.
- Someone said we should do tabs versus spaces next. Oh no. ↩